WordPressで記事が増えてきたころに一括で修正したいようなことってよくあると思うんだけど、Wordpress自体はそういう一括修正のようなものは機能として持っていないので手作業となるとどえらく苦労することに。まぁ事実上無理。
そこでSearch Regexプラグインの登場になるわけだけどググっても単純な文字列の置換についての紹介しか見かけないので書いてみた。
画像1;
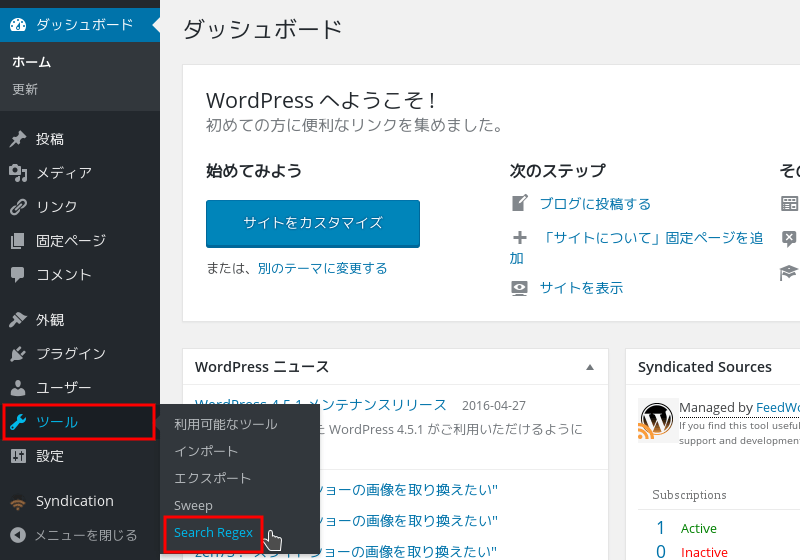
管理画面のツールから「Search Regex」を選ぶ。このツールは管理者画面では1項目だけ。ツールの操作画面も1つだけ。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | <p>桜</p>
<a href="http://example.com/page1.html">リンク1</a>
<a href="http://example.com/page2.html">
リンク2
</a>
<a href="http://example.com/"><br />リンク3</a><br /><a href="http://example.net/"><br />リンク4</a>
大小HijK
0123456789
<img src="http://example.com/dir/abc.webp" />
<img src="http://example.com/dir/def.webp" />
<img src="http://example.org/dir/abc.webp" />
<img src="http://example.org/dir/def.webp" />
信号機の色は赤です
16/05/04
2016/05/04
|
上のような投稿があったとして、以下はこの内容を置換するものとする。
この記事では投稿1つだけのテストサイトでやってるので検索結果や置換結果が少ないけど、実際には全ての投稿や固定記事(など)を対象とするので置換対象が膨大になる場合がある。なお、膨大といっても数万程度ならこのプラグインはサクッと処理できるので大丈夫。大変なのは確認かな。
画像2;
まずは単純な文字列の置換。Windowsの低機能な「メモ帳」にすら実装されている普通の置換機能と同等なので難しいことはない。
Source(WordPressのどの部分を対象とするか)はPost content (投稿と固定記事の本文のこと)を指定。
Search patternには置換対象(マッチさせる文字列)、Replace patternには置換文字列を指定する。
[Search]を押すとSourceからマッチするパターンを探して表示するだけで置換後の表示は無い。データベースは書き換えない(保存されない)ので何度でも試行錯誤できる。
[Replace]を押すとSourceから置換対象を探してマッチするものを表示すると共に置換したらどうなるかも表示する。これもデータベースを書き換えないので何度でも試行錯誤できる。
[Replace & Save]を押すと置換対象を探し置換してデータベースを書き換える。実行してしまうと戻せないような事態もあるので置換対象や置換したらどうなるかもしっかり確認するまではこのボタンは押さない。
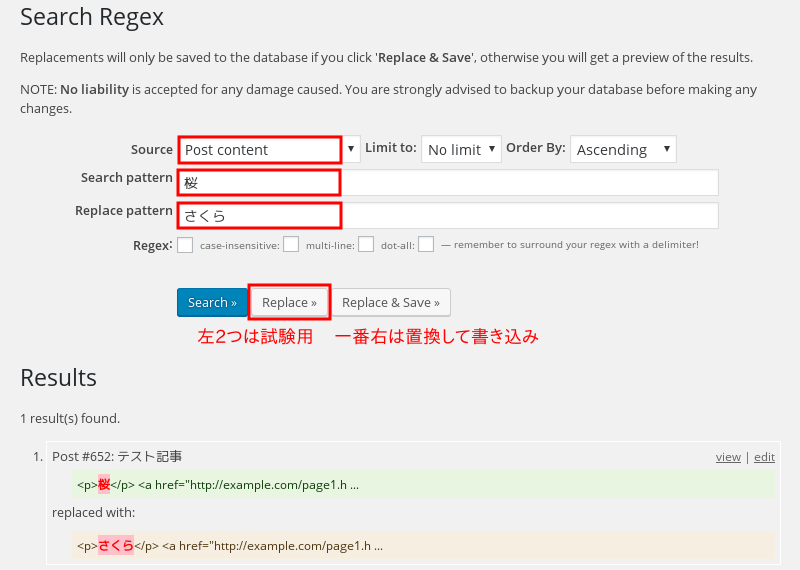
上の画像は「桜」というのを「さくら」に変えたいという場合。単純に置換対象と置換文字列を指定して[Replace]を押した。
下の方に結果が表示される。緑塗りになっているのが検索対象の前後を含む文字列でその中で赤い部分がマッチした検索対象文字列。
黄色塗りになっているのが置換後の状態で前後の文字列を含む。その中で赤い部分が置換文字列。
ここからがこのSearch Regexの本領部分。
たとえばexample.comへのリンクを全て消し去りたい場合は基本的には下のようなタグを探すことになる。
<a href="http://example.com/○○">□□□</a>
おそらくリンク毎に○○や□□□の部分がバラバラなのでワイルドカードや正規表現を必要とする。そこでSearch Regexの正規表現モードを使うために「Regex:」にチェック。
正規表現モードのときは「Regex:」にチェックするだけでなく置換対象の文字列(置換パターン)をデリミタ / で挟む。←この1行見ただけで正規表現を扱い慣れている人は後を読む必要は無いかも。
逆に正規表現に馴染みがないと扱いにくいと思うかもなので下を頭の片隅にでも。
使い方の基本ルール
- 既に書いたが / で置換対象の文字列を挟む。 例: /置換対象/
- 行頭をマッチさせたいならMultilineモードで置換対象に^を付ける。 例: /^置換対象/
- 行末をマッチさせたいならMultilineモードで置換対象に$を付ける。 例: /置換対象$/
- 幾つかの特殊文字 / . * + ^ $ [ ] ( ) { } \ | などはエスケープが必要。
- ワイルドカードは .* として使う * だけでは機能しない。(何か変だが)
- 最長一致と最短一致を意識する。 最短一致で使いたい場合は .*? のように使う。
- コードは途中で改行されて複数行で記述されているかもしれないことを意識する。
エスケープの例
普通に考えて<a href.*example.com.*</a> とするところを
<a href.*example\.com.*<\/a> のように特殊文字の直前に \ を付ける。
なお、\ は日本語環境だと半角の円記号 ¥ を使う。(←の¥は半角の円記号ではないので注意)
画像3;
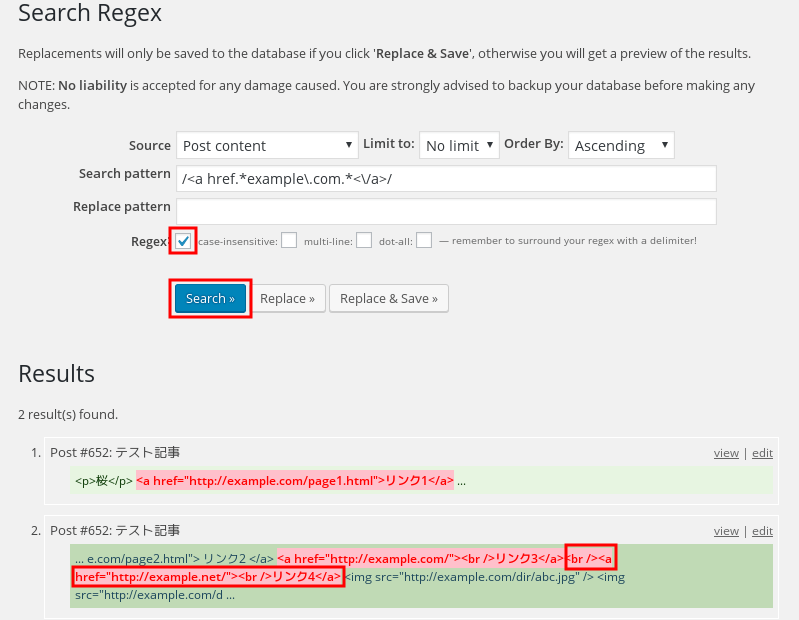
普通に考えて /<a href.*example\.com.*<\/a>/ を置換対象とした。Regexにチェックして検索ボタンを押したところが上の画像。
リンク1は思惑通りにマッチした。しかし、リンク2はマッチせず、リンク3はマッチしているもののリンク4の終わりの</a>まで繋がってマッチしているので正しくない。
これは複数行を探していないのとパターンマッチの規則が最長一致だから。
画像4;
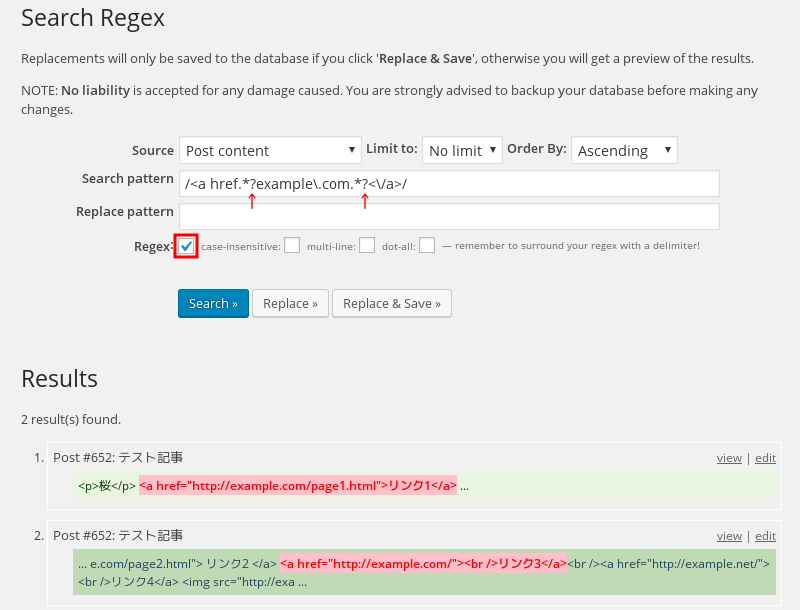
最短一致で抽出したい。そこで置換対象を /<a href.*?example\.com.*?<\/a>/ にする。つまり「?」を追加した。
その結果が上の画像。こんどはリンク1はもちろんリンク3も正しくマッチして、リンク4は (example.netは対象外なので)マッチしていない(正しい動作)。ただしリンク2はマッチしていない。
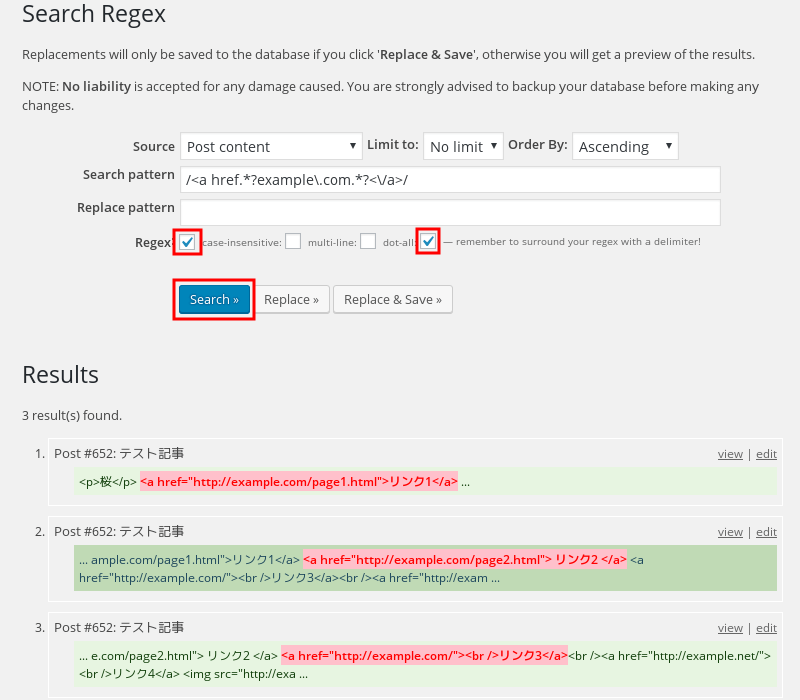
画像5;
リンク2もマッチさせたいので複数行に対応させる。画像4の置換対象のワイルドカード部分に . を含んでいるので「改行も含むすべての文字にマッチ」するモード(perlの正規表現でいうSinglelineモード)でパターンマッチする。(複数行を1行としてパターンマッチさせるので普通に想像するシングルラインとは意味が逆になる)
Search Regexには「dot-all」モードがあるのでチェックすると上の画像。
こんどは複数行に分かれて書かれたリンク2も思惑通りマッチした。
なお、Search RegexのResult欄は改行は無しで表示されるので念の為。
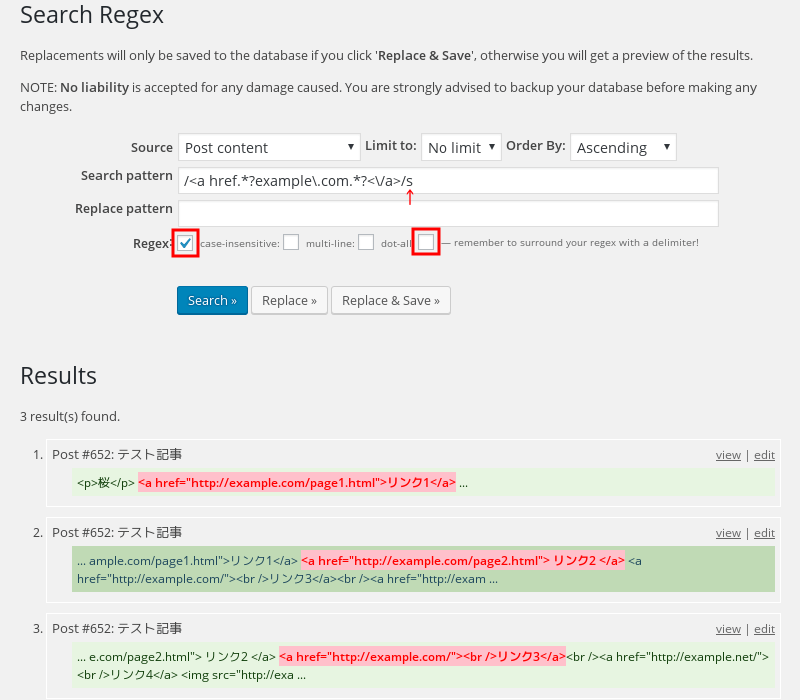
画像6;
dot-allにチェックしないで画像5と同じ結果を得るなら直接パターンマッチ演算子の s を付けて /マッチさせる文字列に.を含む/s のようにする。パターンマッチ演算子を直接付けて機能するんだったらSearch RegexプラグインのチェックボックスはRegexだけで良いんじゃないかと思うんだけど・・どうせ正規表現知らなきゃ使えない部分だし。
ついでにMultilineモードだけど、例えば行頭から0123のような文字列で始まるものをマッチさせたい場合に検索対象を /^0123/ とする。789が行末のような文字列をマッチさせるには検索対象を /789$/ とする。これを使うときはSearch Regexの「Multiline:」にチェックする。またはチェックはしないでパターンマッチ演算子の m をつけて /^0123/m や/789$/m のようにする。
初稿は寝ぼけてSearch RegexのMultilineのチェックが機能してないとかウソ書いてた、スミマセン。
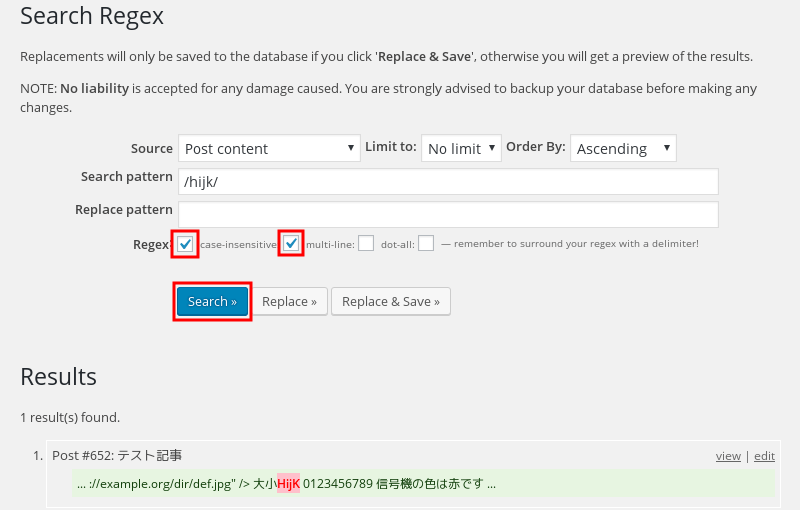
画像7;
アルファベットの大文字小文字を無視して検索する場合は「case-insensitive:」にチェックを付ける。またはRegexオプションとして(デリミタの後に)iを付ける。例: /置換対象/i
上の画像では全て小文字のhijkで検索すると大文字小文字混ざりのHijKが思惑通りマッチした。
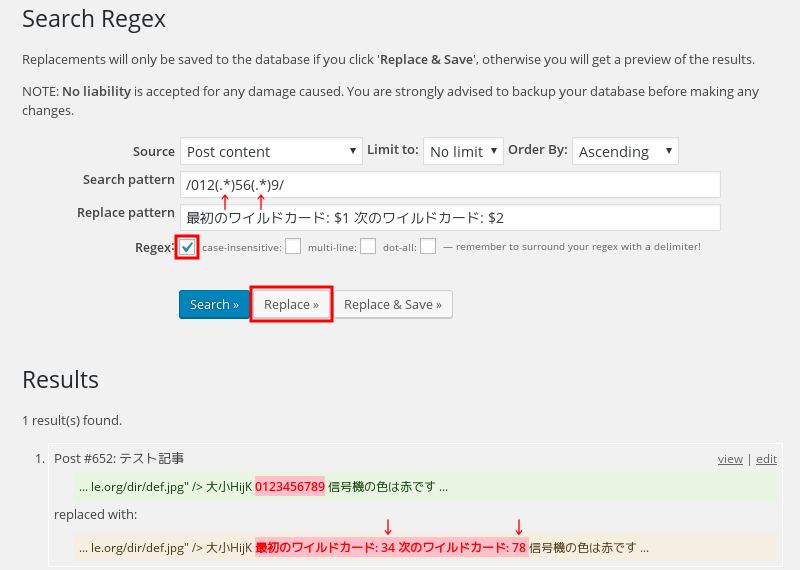
画像8;
パターンの一部をグループとして取り出した置換もできる。
上の例では0123456789から34の部分と78の部分をワイルドカードを括弧で括った2つのグループとして抜き出した。
そのグループを置換文字列として出力する。出力先は$1 $2などなど置換文字列側の括弧で括った順番に対応して数字を付ける。逆に並べて $2 $1 のようにしたり $1 $1 などのように同じグループを複数回使用することも当然できる。
画像9;
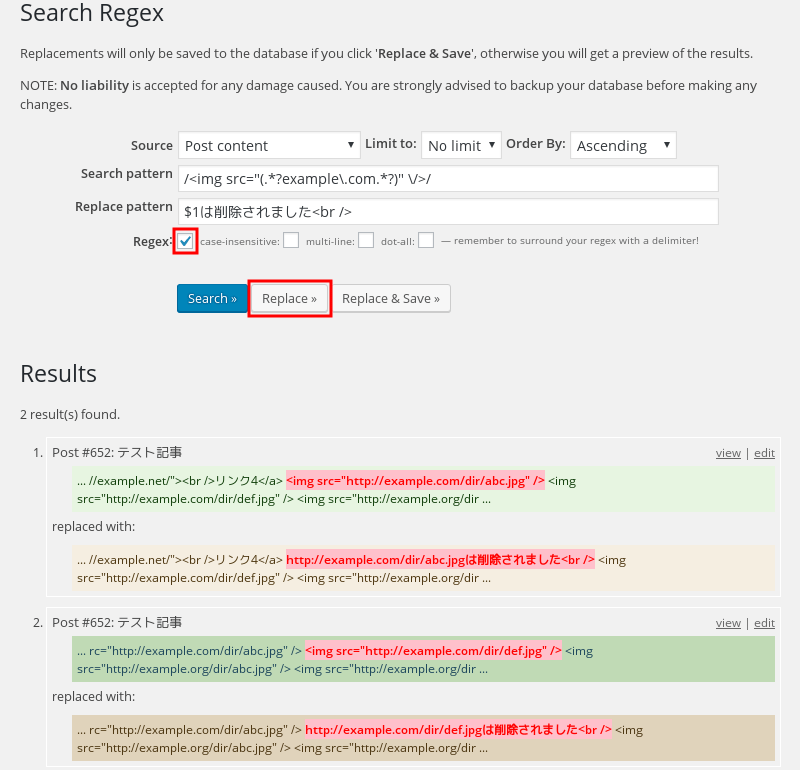
括弧で括った部分が1グループなので上の画像のようにexample.comという文字列を含むURL部分を最短一致で抜き出したものをグループとして抜き置換した。
もちろんexample.orgにはマッチしていない。こういう使い方をすることは何気に多い筈。特に大量にある場合はこういうの出来ないと大変。
画像10;
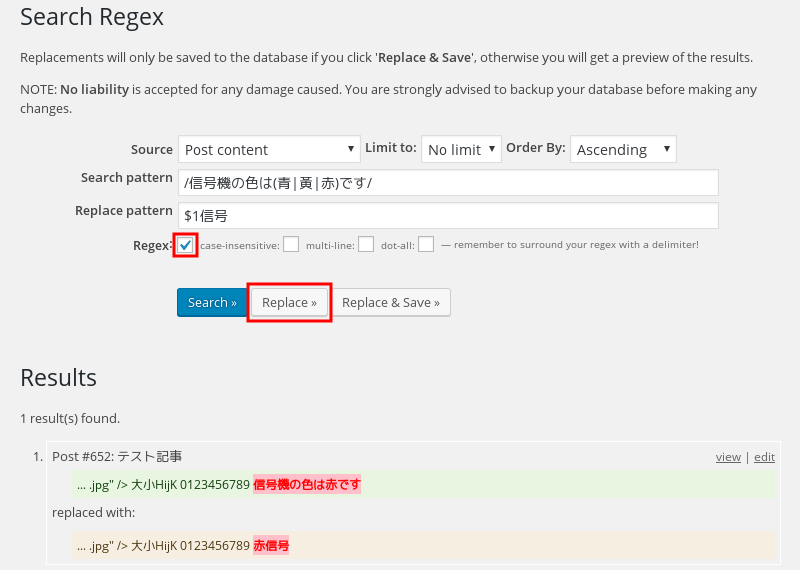
いずれかの文字列(選択パターン)をグループとして抜き出すことも可能。上の例だと /信号機の色は(青|黄|赤)です/ で青、黄、赤のいずれかであればマッチして抜き出される。だから「信号機の色は緑です」だとマッチしない。
画像11;
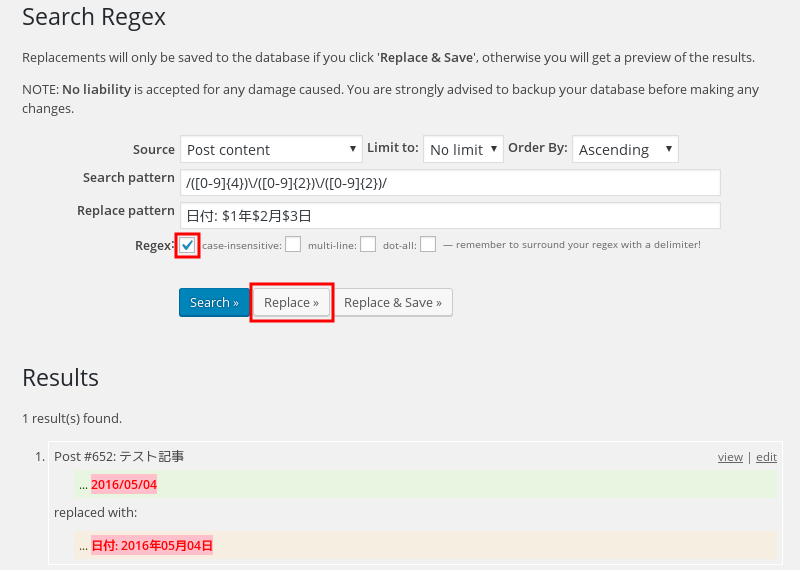
対象文字を絞り込んだり文字数を指定した(文字集合)パターンも作れる。上の例だと /([0-9]{4}\/([0-9]{2}\/([0-9]{2})/ で数字4文字/数字2文字/数字2文字のパターン(例: 2016/05/05)にマッチした場合にその各要素を抜き出している。年月日の区切りの / はエスケープが必要なので \/ になっている。
Search Regexプラグインの使い方というより正規表現のことしか書いてない感じになってるのでこれで終わり。正規表現の方も触りだけだけど。