何年もログの始末が放置されてたのでこの記事を書いたのですが、とたんに本家でほぼ似た内容(ログファイル名も変更があったこととローテート頻度が違う)で修正が入ったのでこの記事の前半はもはや存在意味が失われています。
お家の音楽再生にはRaspberry Pi Zero W+Volumioを使っている。SDカードが壊れたとか更新したら新しい版のバグで動かなくなったとかはあったけど、そういう突発的な事故以外は基本的には調子が良い。メンテナンスもほぼ不要なので「管理」もほぼ不要。
気に入らないのは、ログの処理が手抜きになっているので使い続けるとログでファイルシステムが溢れてしまうこと。家のRaspberry Pi Zero Wの環境だと/var/logは21MBしか割り当てられていないので使い方によっては数日程度で溢れることも。
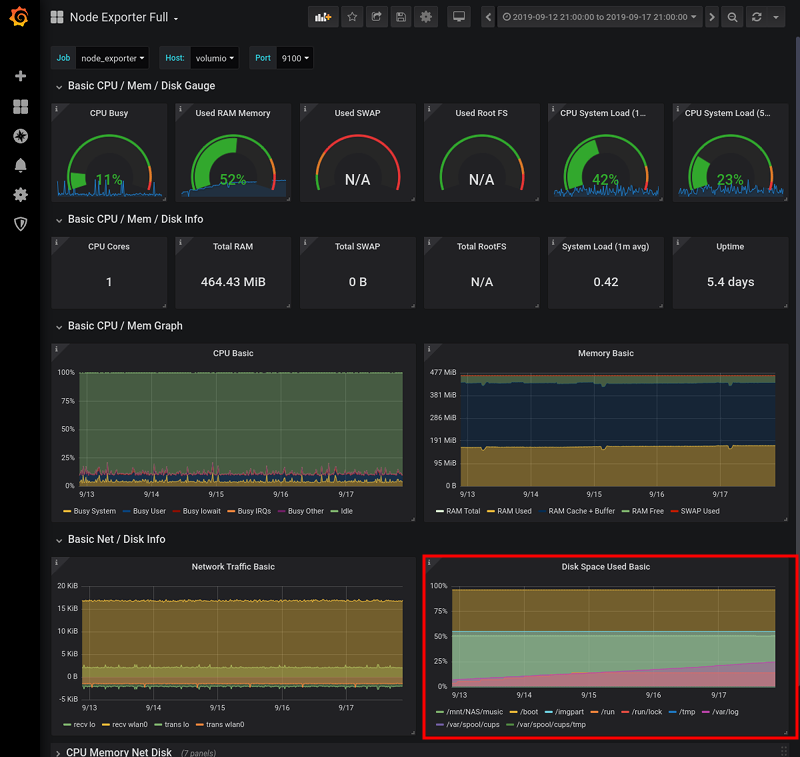
Prometheus+Node Exporterで監視しているVolumioの状況。右下のグラフが気になる。(次)
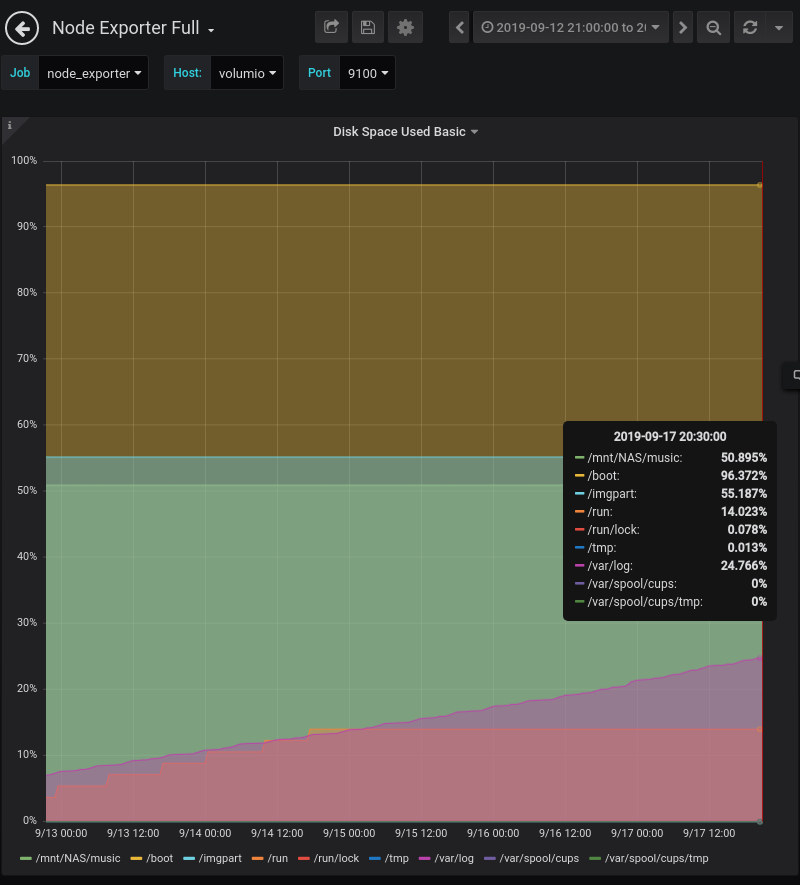
Volumioを再起動して翌日からウェブラジオを5日以上連続視聴していたときのディスクスペースの監視グラフ。
紫色が /var/log の使用状況。5日で8%から24%まで16%増加している。つまり、このままこのウェブラジオの視聴というか再生を続けたら1ヶ月ほどで /var/log は溢れてしまうことになる。
Volumioでは幾つかのログが記録されるが、特に肥大し易いのは /var/log/volumio.log 。
このログファイルにはVolumioで操作した内容やそれに伴う処理がバカスカ書き込まれる。統計情報にも使えるので要らないというものではない。このログが適切に処理されずに放置されているのでファイルシステムが溢れる。以前はログがいっぱいになるとVolumioが動かなくなった記憶があるが、最近はそれで動かなくなるということは無いみたい。ただし、ログが追記できない状態のままになる。一応、Volumioを再起動するとログファイルは消えるので問題は解消されるのだが、正しくログを出力したければ、ある程度使い続けたら必ず再起動しなければならない。これはスマートじゃない。
VolumioはLinuxなので、システムのlogrotate(ログローテート)を使ってログファイルを管理すれば良いんじゃね?ということになるよね?
残念なことにVolumioではログローテート用の設定ファイルの一部は存在するようだけどlogrotateの実体が存在しない。
そこで、今回はログローテートのインストールと設定。
logrotateのインストール
$ apt-cache search logrotate ←リポジトリに存在するlogrotateというキーワードを含むパッケージを検索
erlang-lager - logging framework for Erlang
logrotate - Log rotation utility ←これをインストールしたい
パッケージにlogtotateが含まれるようなのでそれをインストールする。
$ sudo apt install logrotate
設定
logrotateのメインの設定ファイルは /etc/logrotate.conf だが、 /etc/logrotate.d ディレクトリの中の設定ファイルもインクルードされるということになっているので、 /etc/logrotate.conf は触らず、 /etc/logratate.d の下にvolumioというファイルを作成してそこに設定を書く。
/etc/logrotate.d/volumio (新規作成)1 2 3 4 5 6 7 8 | /var/log/volumio.log {
daily #←毎日ローテートする
missingok #←ファイルが無くてもエラーにしない
rotate 1 #←ローテートする世代数 この場合は1世代だけ残す
copytruncate #←新しいファイルを作るのではなく既存ファイルを空にする
nocompress #←ローテーションしたファイルを圧縮しない
notifempty #←ログが空ならローテートしない
}
|
$ sudo logrotate -dv /etc/logrotate.conf
確認の実行でvolumioのログについてエラーにならないこと。
手動実行
$ sudo logrotate /etc/logrotate.conf
実際にログがローテートするので注意。
-fオプションを付けて強制実行してみるのもアリ。
確認
$ cat /var/lib/logrotate/status
logrotate state -- version 2
"/var/log/dpkg.log" 2019-9-23-6:0:0
"/var/log/apt/term.log" 2019-9-23-6:0:0
"/var/log/apt/history.log" 2019-9-23-6:0:0
"/var/log/samba/log.smbd" 2019-9-23-6:0:0
"/var/log/alternatives.log" 2019-9-23-6:0:0
"/var/log/wtmp" 2019-9-24-0:26:42
"/var/log/volumio.log" 2019-9-24-0:26:42 ←volumio.logがあることを確認
"/var/log/btmp" 2019-9-24-0:26:42
"/var/log/exim4/paniclog" 2019-9-23-6:0:0
"/var/log/samba/log.nmbd" 2019-9-23-6:0:0
"/var/log/exim4/rejectlog" 2019-9-23-6:0:0
"/var/log/exim4/mainlog" 2019-9-23-6:0:0
"/var/log/samba/log.winbindd" 2019-9-23-6:0:0
ログのあるディレクトリを見てみる。
$ ls -l /var/log
total 44
-rw-r--r-- 1 root root 5560 Sep 24 00:53 boot.log
-rw-rw---- 1 root utmp 0 Sep 24 01:22 btmp
-rw------- 1 root utmp 0 Sep 24 00:53 btmp.1
-rw-r--r-- 1 root root 428 Sep 24 01:15 mpd.log
-rw-r--r-- 1 volumio volumio 0 Sep 24 01:22 volumio.log ←volumio.logは空になる
-rw-r--r-- 1 volumio volumio 11526898 Sep 24 01:22 volumio.log.1 ←volumio.logの1世代前が作られている
-rw-rw-r-- 1 root utmp 0 Sep 24 01:22 wtmp
-rw-rw-r-- 1 root utmp 1920 Sep 24 00:57 wtmp.1
volumioを操作(楽曲再生・停止など)してから再度ファイルサイズを確認する。
$ ls -l /var/log
total 44
-rw-r--r-- 1 root root 5560 Sep 24 00:53 boot.log
-rw-rw---- 1 root utmp 0 Sep 24 01:22 btmp
-rw------- 1 root utmp 0 Sep 24 00:53 btmp.1
-rw-r--r-- 1 root root 428 Sep 24 01:15 mpd.log
-rw-r--r-- 1 volumio volumio 15031 Sep 24 01:22 volumio.log ←volumio.logのファイルサイズが増えること
-rw-r--r-- 1 volumio volumio 11526898 Sep 24 01:22 volumio.log.1
-rw-rw-r-- 1 root utmp 0 Sep 24 01:22 wtmp
-rw-rw-r-- 1 root utmp 1920 Sep 24 00:57 wtmp.1
ログをローテートした後に/var/log/volumio.logにログが書き込まれなければ失敗。これだけはしっかり確認した方が良いでしょう。
一応、logrotateの設定でcopytruncateを指定しているので正しく動作する筈。
自動実行
手動で実行してログがローテートできても、これが毎日自動的に行われなくては意味がない。
でも、Volumioのlogrotateパッケージはlogrotateをサービスとして登録してくれない。
/lib/systemd/system/logrotate.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | [Unit]
Description=Rotate log files
Documentation=man:logrotate(8) man:logrotate.conf(5)
ConditionACPower=true
[Service]
Type=oneshot
ExecStart=/usr/sbin/logrotate /etc/logrotate.conf
# performance options
Nice=19
IOSchedulingClass=best-effort
IOSchedulingPriority=7
# hardening options
# details: https://www.freedesktop.org/software/systemd/man/systemd.exec.html
# no ProtectHome for userdir logs
# no PrivateNetwork for mail deliviery
# no ProtectKernelTunables for working SELinux with systemd older than 235
# no MemoryDenyWriteExecute for gzip on i686
PrivateDevices=true
PrivateTmp=true
ProtectControlGroups=true
ProtectKernelModules=true
ProtectSystem=full
RestrictRealtime=true
|
1 2 3 4 5 6 7 8 9 10 11 | [Unit]
Description=Daily rotation of log files
Documentation=man:logrotate(8) man:logrotate.conf(5)
[Timer]
OnCalendar=daily
AccuracySec=12h
Persistent=true
[Install]
WantedBy=timers.target
|
これで systemctl enable logrotate とでもすればよいのでしょうか?(試していない)
ただ、cronをインストールしていれば、logrotateをサービスとして登録する必要は無いので、今回はcronを使うことに。
なお、Volumioではcronも標準ではインストールされていないので別途インストールが必要。
[参考] cronのインストール
$ sudo apt-cache search cron ←リポジトリにある「cron」の文字列が含まれるパッケージを検索 anacron - cron-like program that doesn't go by time python-apscheduler - In-process task scheduler with Cron-like capabilities python3-apscheduler - In-process task scheduler with Cron-like capabilities apticron - Simple tool to mail about pending package updates - cron version apticron-systemd - Simple tool to mail about pending package updates - systemd version bcron - Bruce cron system cron - process scheduling daemon ←これをインストールする cron-apt - automatic update of packages using apt-get cron-deja-vu - filter for recurring cron mails cronic - Bash script for wrapping cron jobs to prevent excess email sending cronolog - Logfile rotator for web servers 後略 $ sudo apt install cron ←cronのインストール 依存パッケージについて何か聞かれたら y/etc/crontab (1行追加)
0 0 * * * root logrotate /etc/logrotate.conf >/dev/null 2>&1
毎日0:00にログローテートを実行する場合。
少なくとも日付が変わった後に正しくログローテートが実行されていることを確認する。
Volumioのタイムゾーン設定を変更していない場合は、初期値はUTCなので0:00のイベントは日本時間では9:00に実行されます。 タイムゾーンの変更は以下。
$ sudo dpkg-reconfigure tzdata
少し待たされてメニューが2画面表示されるのでそれぞれAsiaとTokyoを選択する。
Current default time zone: 'Asia/Tokyo'
Local time is now: Thu Sep 26 20:10:24 JST 2019.
Universal Time is now: Thu Sep 26 11:10:24 UTC 2019.
こんな感じ。
一応、cat /etc/timezoneで内容が Asia/Tokyo になっていることを確認しておく。
Volumioのシステムを再起動する。
$ ls -l /var/log
total 380
-rw-r--r-- 1 volumio volumio 423 Sep 28 00:23 albumart.log
-rw-r--r-- 1 root root 5692 Sep 27 09:56 boot.log
-rw------- 1 root utmp 384 Sep 28 10:27 btmp
-rw-r--r-- 1 root root 670 Sep 27 10:49 mpd.log
-rw-r--r-- 1 volumio volumio 311037 Sep 28 10:26 volumio.log
-rw-r--r-- 1 volumio volumio 950230 Sep 28 00:00 volumio.log.1 ←ファイルの時刻が00:00ならOK
-rw-rw-r-- 1 root utmp 2688 Sep 28 10:27 wtmp
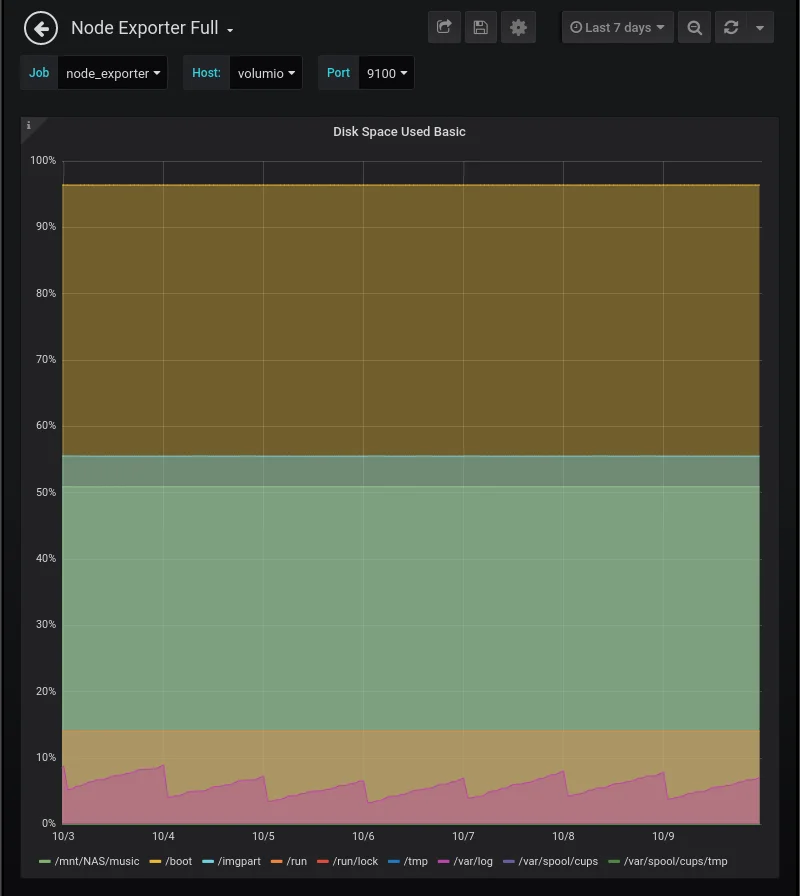
ログローテートを仕掛けてVolumioでウェブラジオを1週間連続再生したときのファイルシステムの使用状況グラフ。(7日間)
毎日0時に/var/logを示すピンクのグラフが下がって鋸刃の形になっている。Volumio.logを非圧縮で1世代残しているので容量が下がってもゼロにはならない。およそ半分に下がるのでこれで正常。
おまけ
Volumioのサーバは以前から帯域制限をしているので転送速度がとても遅かったが、最近は遅いだけでなく繋がりにくい。パッケージのインストールもVolumioのサーバーに接続できなくて失敗することがある。失敗した場合は成功するまで繰り返す。
- Volumioのライブラリ管理をメディアサーバに任せる
- Volumioでコンピレーションアルバムを増殖させないメタデータ
- Volumioにウェブラジオ局を登録
- Volumioのログをローテートする
- Prometheus2とGrafana6によるシステム監視 シングルボードコンピュータの温度表示
- Volumioでradio paradiseを高品質な音で聴く
- Volumioの時刻設定
- Linuxでオーディオファイルにタグを付ける (ファイル名から)
- ELK Stackでシステム監視 Filebeatで収集したVolumioのログから時系列の再生曲名リストを表示
- VolumioのYoutubeプラグインを使ってみる
- VolumioのIPアドレスを調べて接続する
- ELK Stackでシステム監視 FilebeatでRaspberry Pi Zero WのVolumio楽曲再生ランキング
- ELK Stackでシステム監視 MeticbeatでRaspberry Pi Zero WのVolumioを監視
- BubbleUPnP for DLNA/ChromecastでVolumioを操作
- Volumio2がDLNA/UPnPに対応
- NanoPi NEO2 + DACで音楽プレーヤーVolumioを使う
- Raspberry Pi Zero W + volumioでもう少し遊ぶ
- どうしてもWindowsの共有フォルダが見えない対処
- Raspberry Pi Zero W + DACで音楽プレーヤーVolumioを使う