Cloudflareのプロクシ(CDN)を使っている人はそれなりに多そうだが、レジストラを使っている人は多いのかな?現在はCloudflareのレジストラでドメイン取得もできるようになっている?かもしれないが、元々他所のレジストラで取得したドメインをCloudflareに移管することだけができるようになっていて、ドメインの移管に慣れていない人にとっては何をどうしたらよいのかよくわからなかったかも。
「がとらぼ」の中の人はドメインを移管するのは日常茶飯事で、普段はNamecheap, Hover, Internetbs、日本だと「お名前.com」のようなレジストラを使用していてそれらのレジストラ間でドメインを移管させているが、今回初めてCloudflareへのドメイン移管を行った。基本的にはCloudflareではない他所のレジストラ間でのドメイン移管とほぼ同じ要領で移管できた。移管の部分ではCloudflareだから何か特別というのはない。ドメインの更新料が他所のレジストラより「お安め」っていうだけ。ただし、Cloudfalreでは他所のレジストラとは違い、Cloudflareで対象ドメインのDNSを管理できる状態にしないとドメイン移管手続きができない。
今回はCloudflareのレジストラとDNSだけを使用することにする。DNSは「ビジネス」プラン以上ではCloudflare以外のDNSサーバ(自前のとか)を選択して利用できるようだが今回は「無料」プランを利用するのでCloudflareのDNSを使わざるをえない。しかし、これまで自前のDNSサーバ(Bind9)は異常にアクセスが増えると不甲斐なくも落ちてしまうことが度々発生していたので耐性高めで良さそうなところを探していたということもあり、CloudflareのDNSなら文句ないかも。サーバ自前教の信者の人でなければDNSくらいは他所にまかせても良いよね?
DNSサーバの切り替え
手順1:
Cloudflareではドメインを移管する前にCloudflareでその移管対象のドメインのDNSを管理できる状態にしなくてはならない。(他所のレジストラは逆で、そのレジストラへの移管後でないとDNSを利用できるサービスがあったとしてもそのDNSを利用できない)
今回はCloudflareのプロクシ等の他のサービスを利用していないドメインをCloudfalreに登録してDNSを登録するところから。
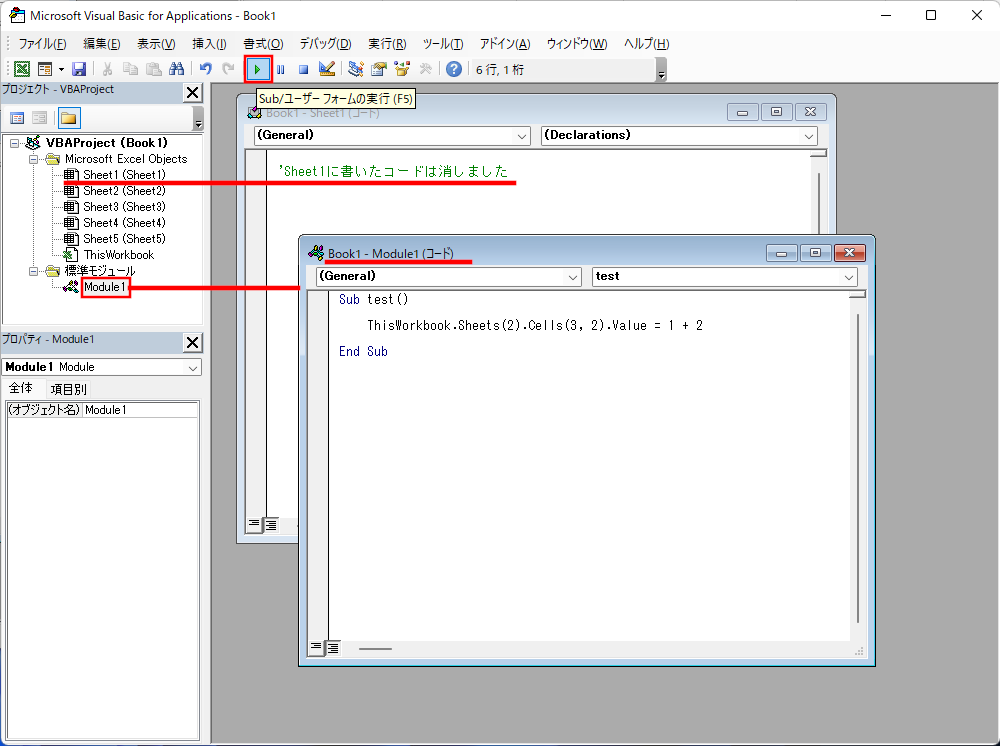
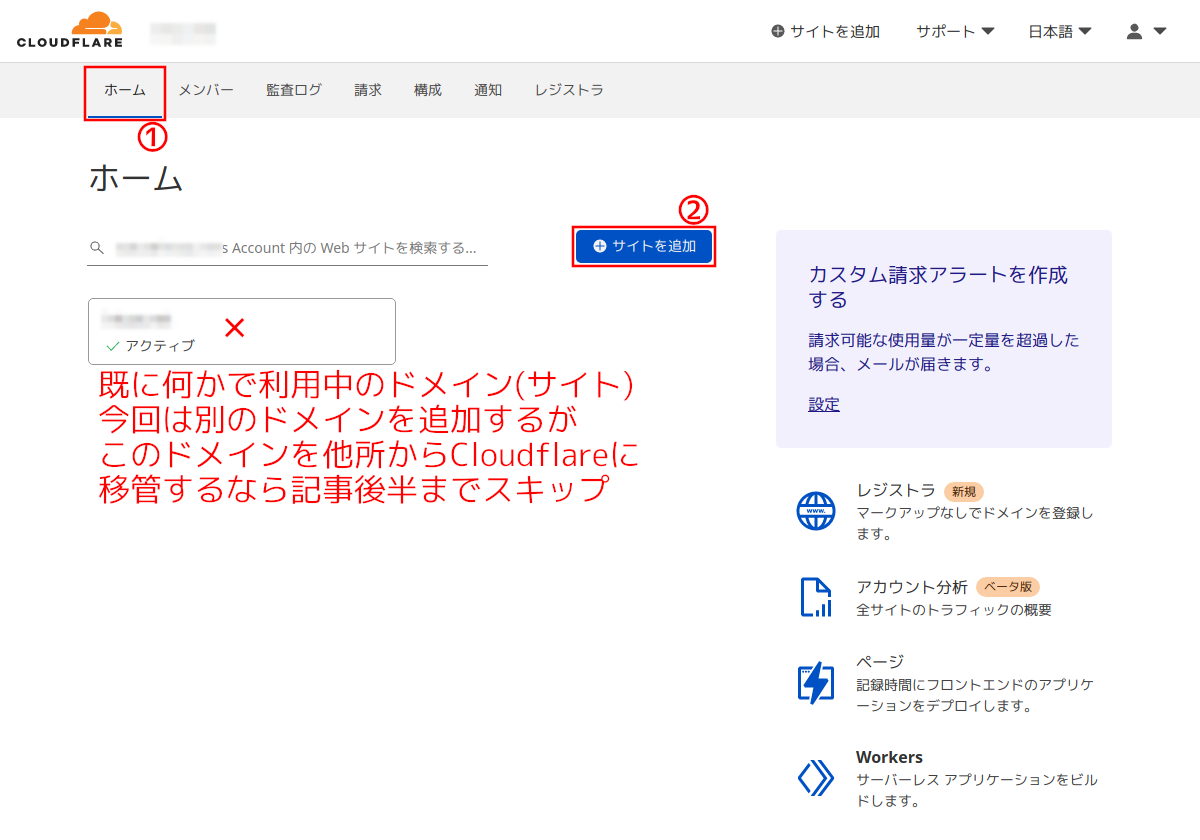
Cloudflareのアカウントを作る部分は省略して、Cloudflareにログインした状態でトップページ(ホーム)から「サイトを追加」をクリック。
手順2:
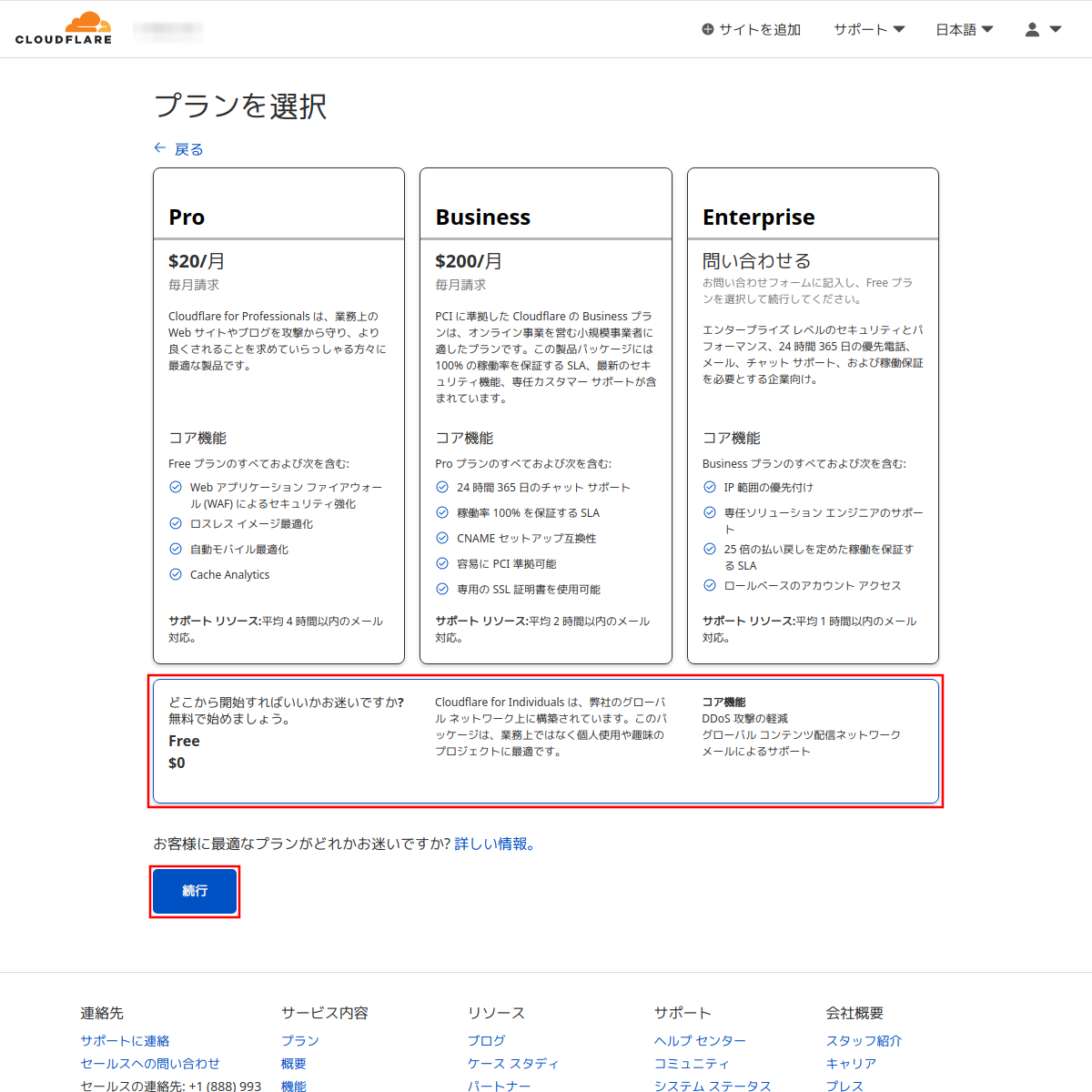
Cloudflareに移管する予定のドメインのDNSを登録するので「無料」プランを選択する。ある程度の規模のウェブサイトでプロクシサービス(CDN)などの利用を検討しているなら「Pro」プラン以上の選択もあるかも。
手順3:
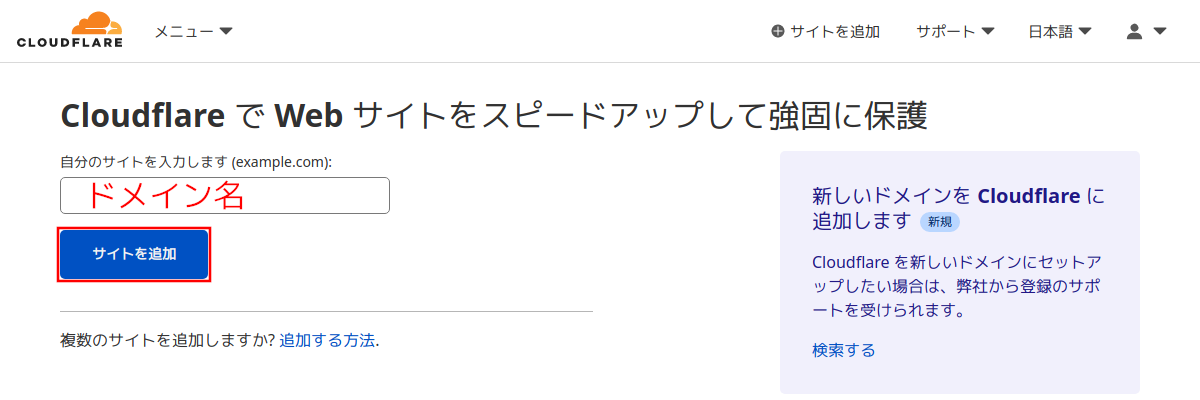
DNSを登録する(その後にドメインを移管する)サイトのドメイン名を入力して「サイトを追加」をクリックする。
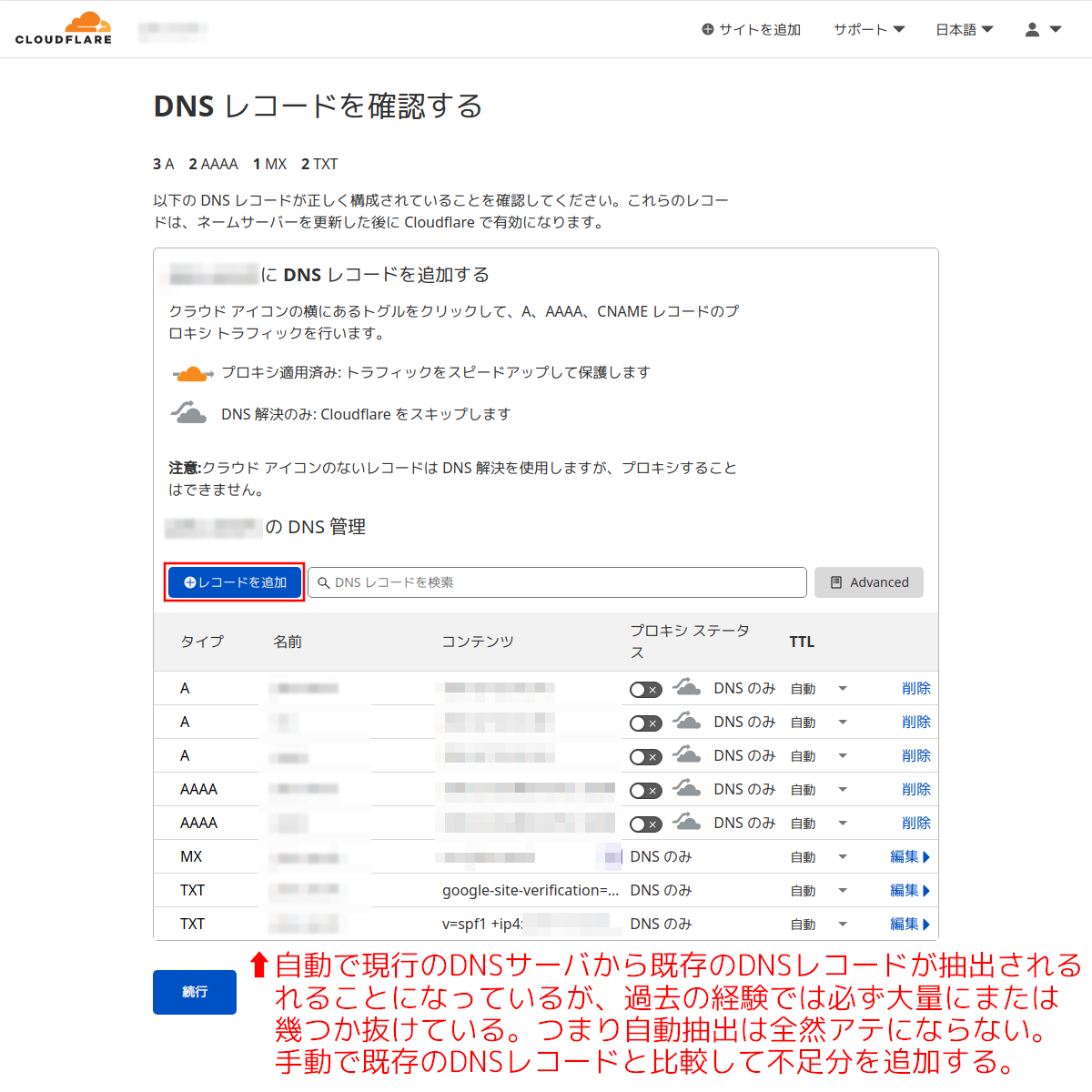
手順4:
入力したドメイン名から現行のDNSレコードが自動的に抽出される。これが完全に行われるなら非常にラクだが、これまでに試した範囲ではこのDNSレコードの抽出はレコード数の多い少ないに関係なくスッカスカに抜けてしまうので、自動にまかせて安心するととんでもないことになるかも。必ず現行のDNSレコードと突合して漏れのないように。
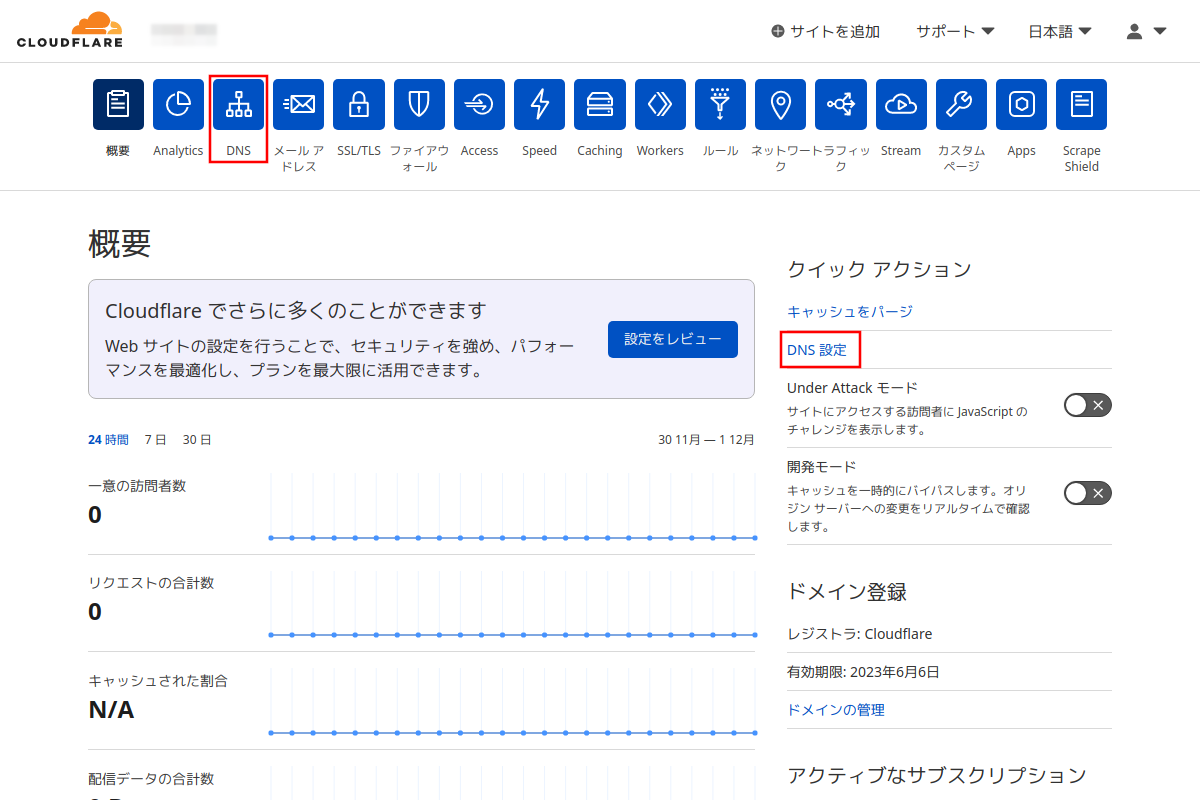
手順5:
上の2つの手順で新規ドメインを登録する場合ではなく、Cloudflareに登録済みのドメインの場合はCloudflareのトップページでドメインを選択してから「DNS」の設定をする。(画像の赤枠のどちらか)
ただし、この場合はドメインのDNSは設定済みな筈なのでここで選択してDNS設定を行う必要はないかも。
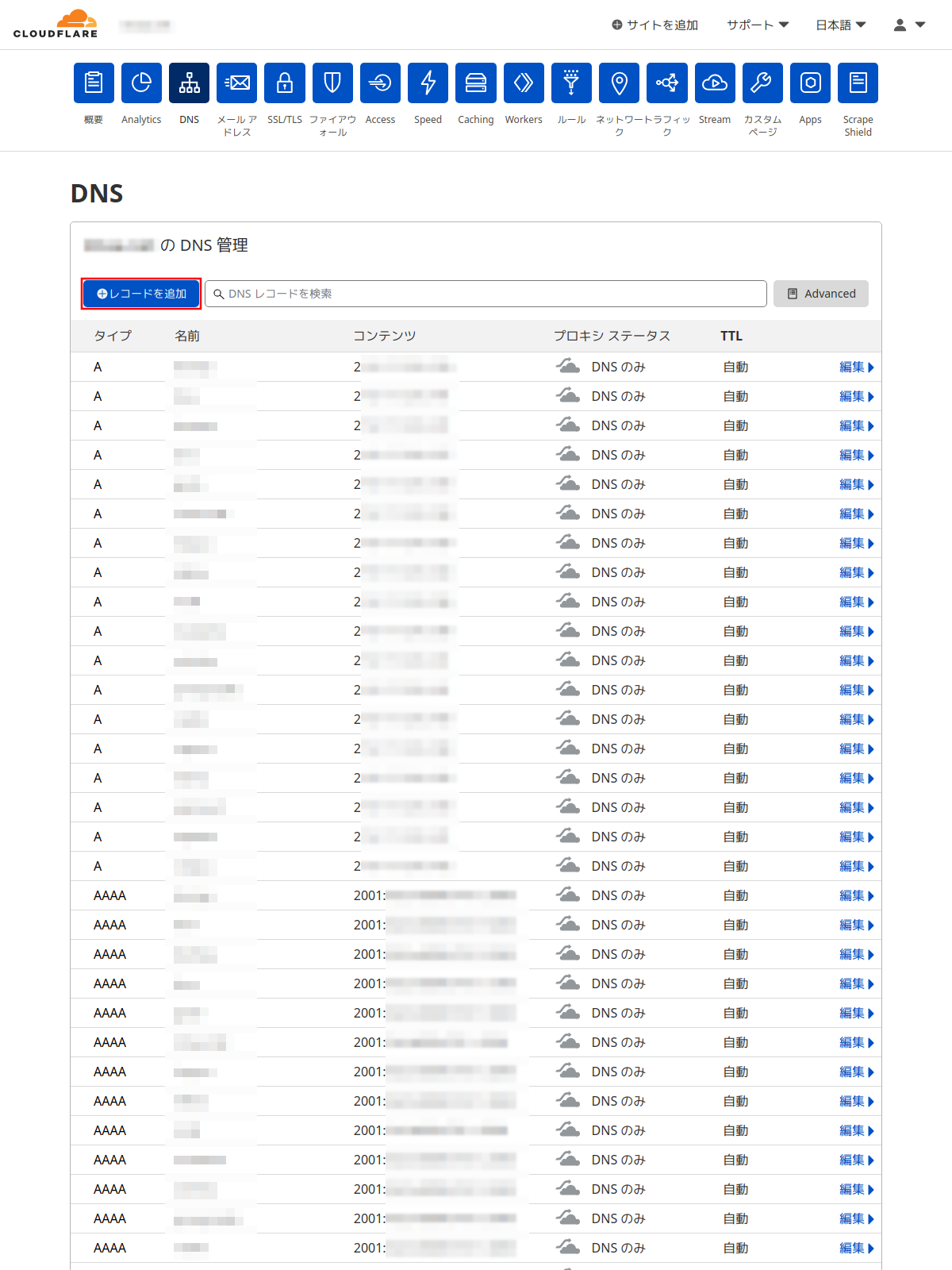
手順6:
(手順4と同じ状態。)
Cloudflareに登録済みのドメインの場合、DNSの設定画面でレコードリストが表示されるので必要に応じてレコードの追加や修正を行う。大抵の場合は修正は要らない筈だと思うけど。
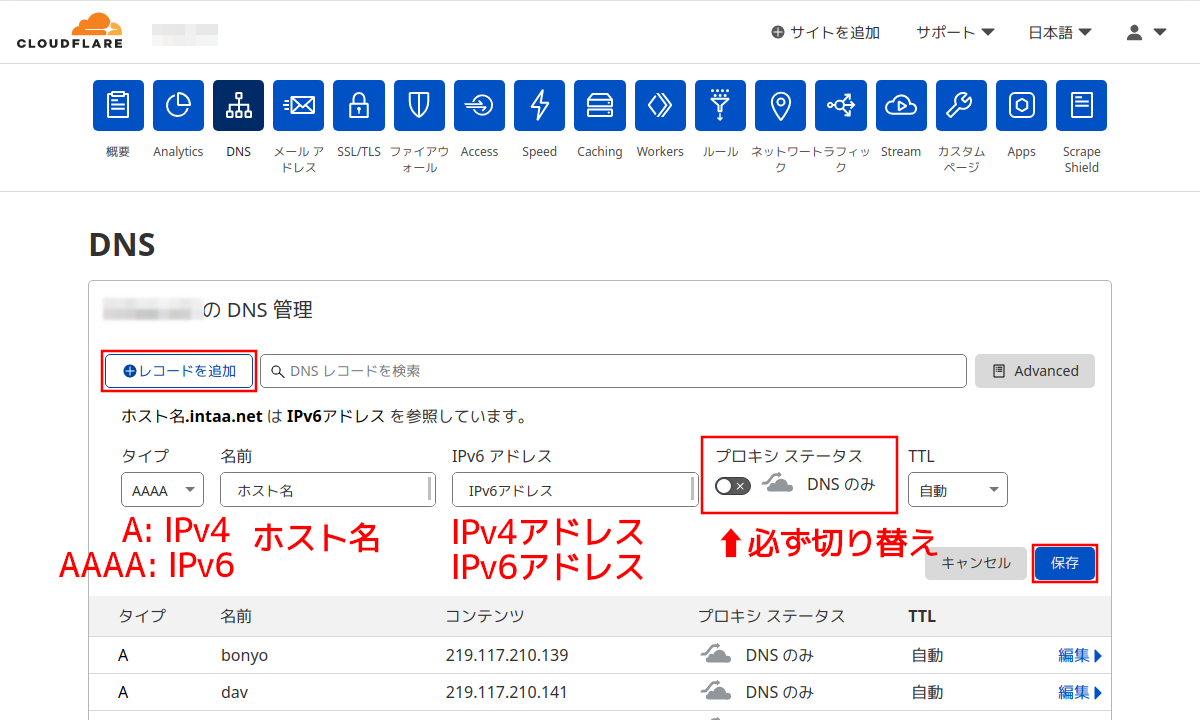
手順7:
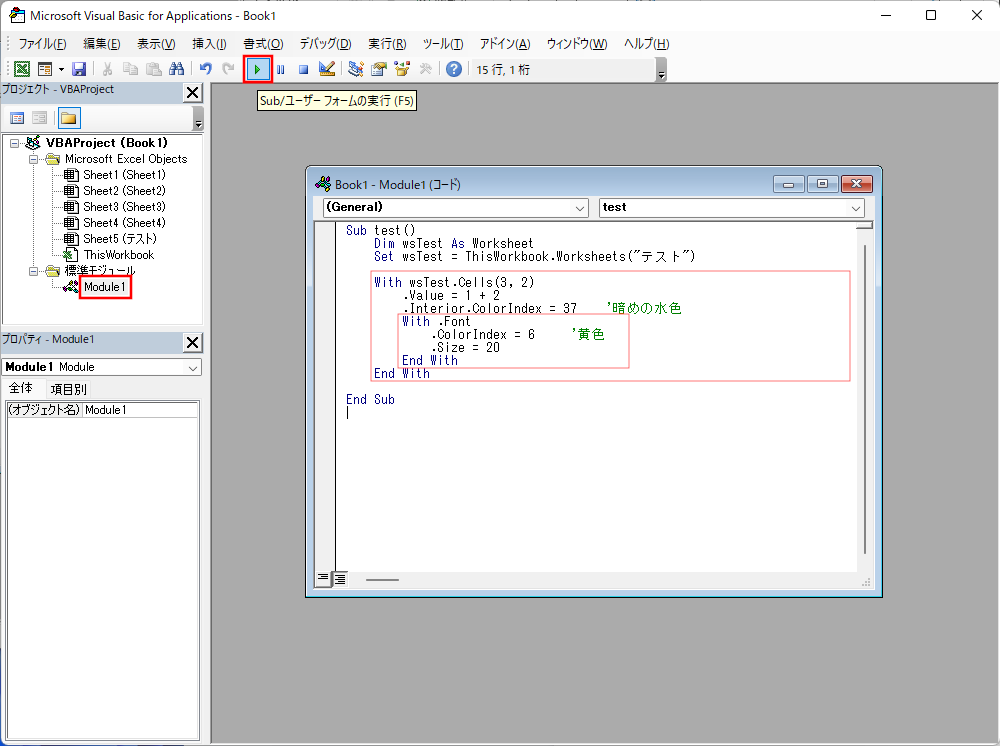
レコードの追加で「ホスト名とIPアドレス」の場合は、「レコードの追加」ボタンをクリックして、タイプにAまたはAAAA、ホスト名はFQDNではなく本当にホスト名だけ、IPアドレスはAレコードならIPv4アドレス、AAAAレコードならIPv6アドレスを入力。プロキシのスイッチはデフォルトはオンだけどCloudflareのプロクシを使うのでなければオフにする。DNSだけを使うならオフで。
「保存」ボタンをクリックする。
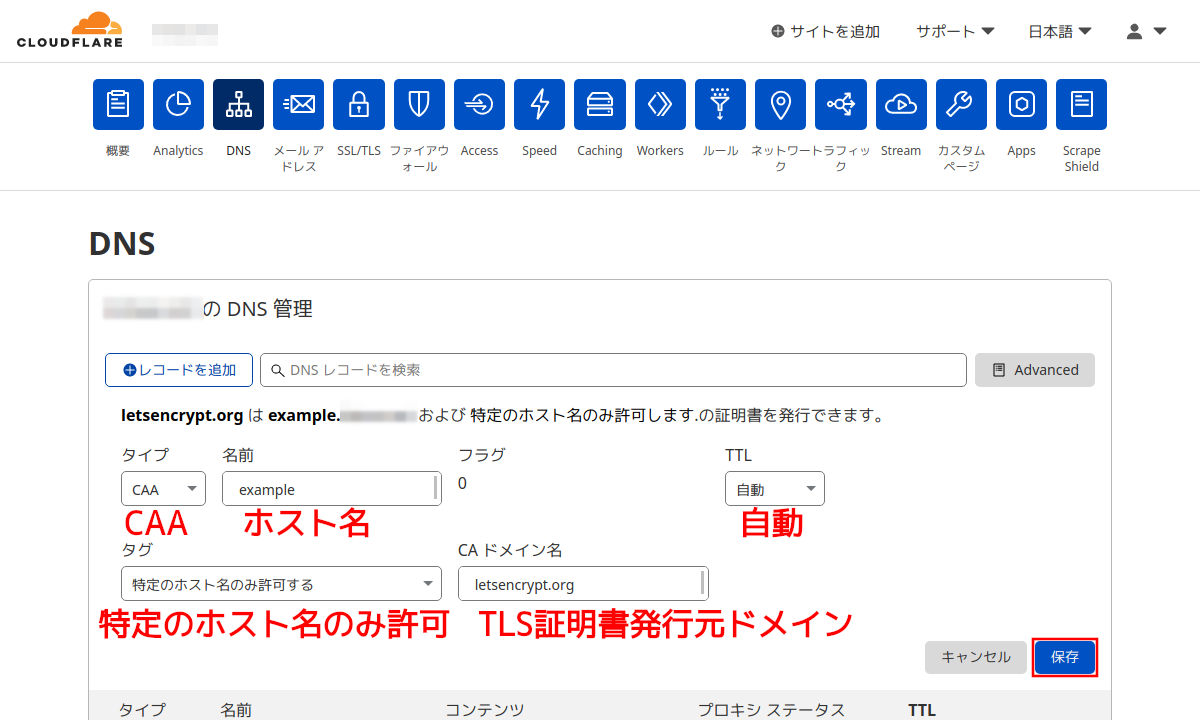
手順8:
CAAレコード登録はわかりにくい。
example IN CAA 0 issue "letsencrypt.org" の場合
「タイプ」はCAA、「名前」にホスト名を入力、「TTL」は自動(初期値)、「タグ」は特定のホスト名のみ許可する(初期値)、CAドメイン名はSSL/TLS証明書の発行ドメイン名(Let's Encryptならletsencrypt.org)を入力。
「保存」ボタンをクリックする。
なお、Cloudflareのプロクシサービスを使用する場合はそのホストのCAAレコードを下手に設定するとCloudflareのTLSが有効化できなくなるので十分に注意
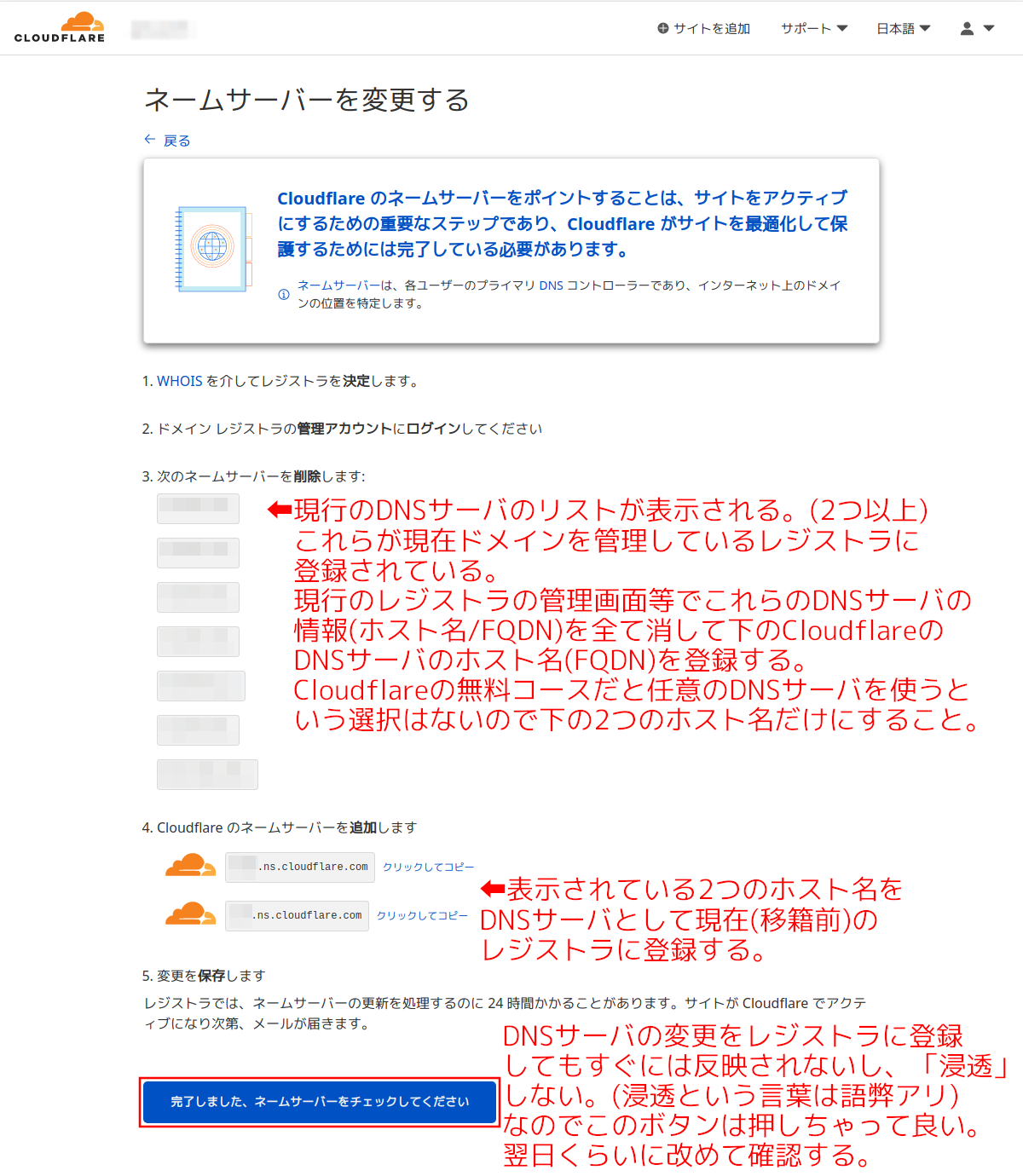
手順9:
新しくドメインをCloudflareに登録する場合は手順4の画像の左下の「続行」でこの画面になる。
現行のDNSサーバがリスト表示される。それは現在のレジストラに登録されているもの。これらのホストを全て現行のレジストラのDNSサーバリストから外す。代わりにCloudflareのDNSサーバ2つを現在のレジストラに登録する。(それは手順11へ)
CloudflareのDNSサーバ2つをメモったら一番下の「完了しました。ネームサーバをチェックしてください」を押す。レジストラ側のDNS登録変更前でも可。
登録済みドメインではこの画面にはならないので手順11へ。
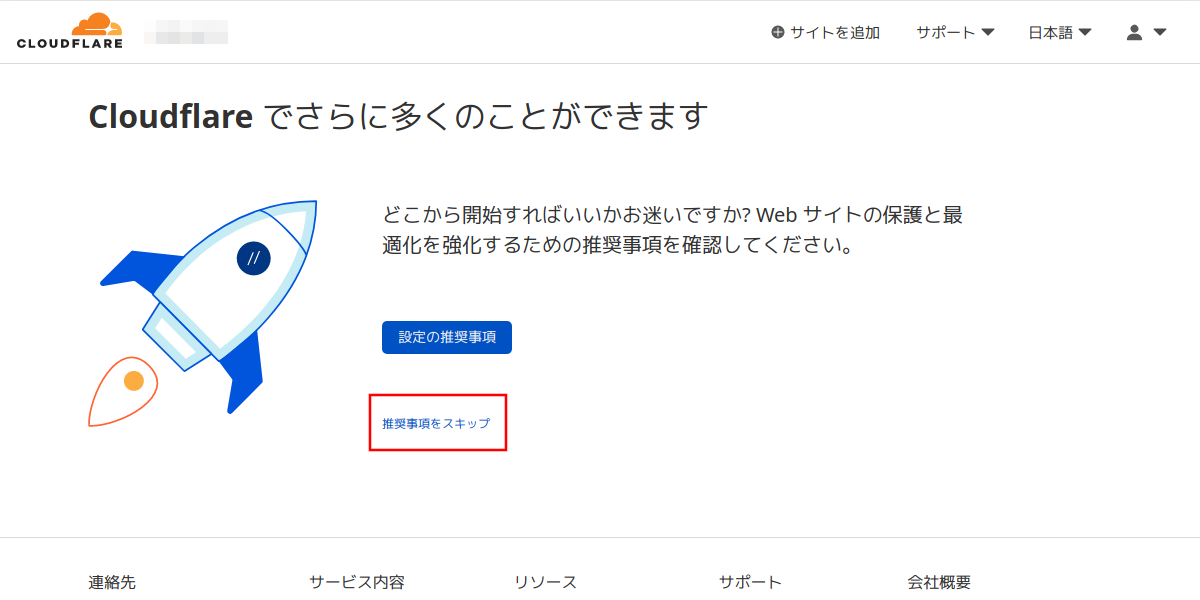
手順10:
まだ現行のレジストラでDNS登録変更をしていない。現行のレジストラでDNSの変更登録をするまではCloudflare側で何を設定しようが何も効果はない。また、レジストラでのネームサーバの変更はすぐに反映せず1時間から1日程度かかると思った方が良い。そこで、とりあえず翌日くらいまでCloudflareの方は放置で。
「推奨事項をスキップ」をクリックするかブラウザを閉じる。
なお、今回のやり方では権威DNSサーバは変更になるがゾーンデータは(基本的には)変わらないので「所謂ところの浸透」という部分では神経質になる必要はないので(次のDNSサーバの登録変更後に)Cloudflare側でDNSサーバの変更を認識できたらTTL切れを待つことなく次に進んで良いと思う。(「浸透」という言葉が嫌いな人はスミマセン)
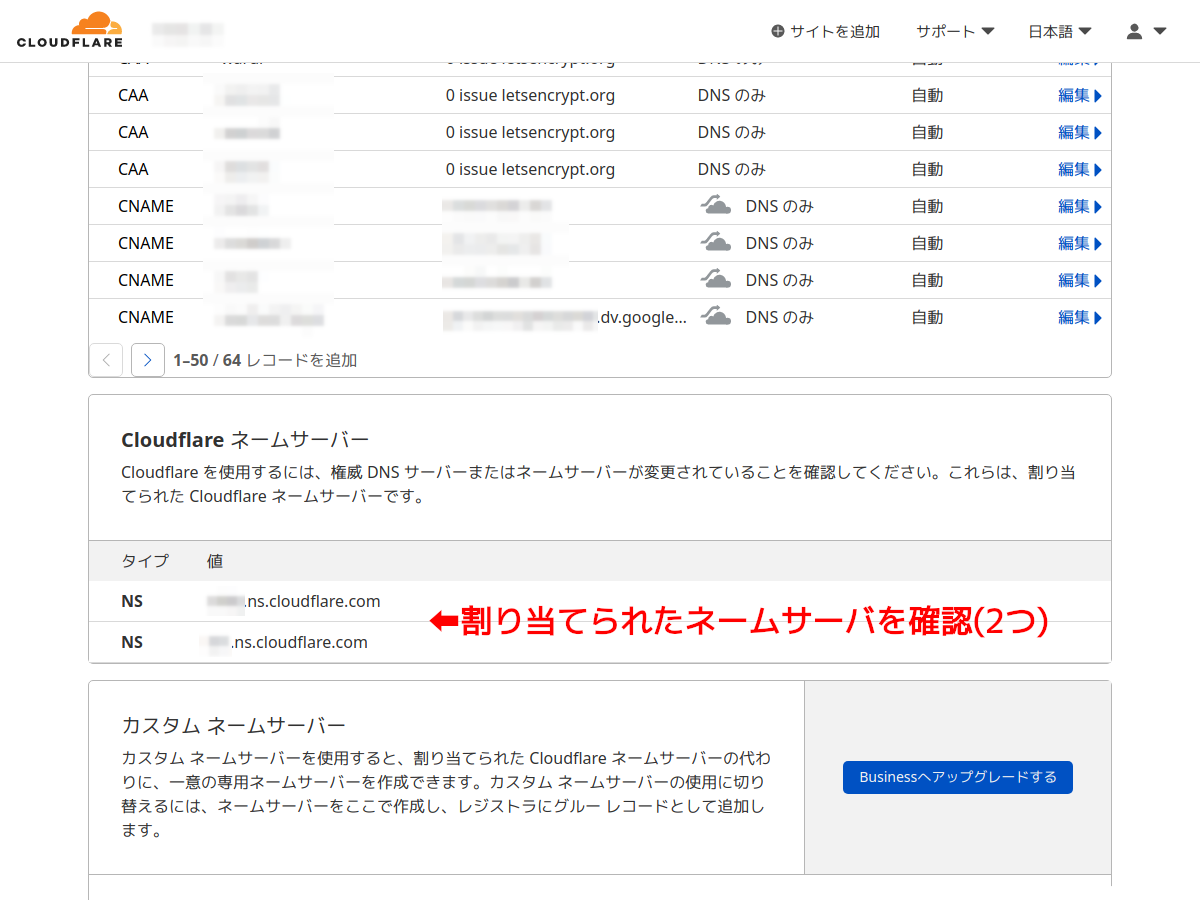
手順11:
Cloudflareの登録済みドメインの場合は、現在のレジストラのDNSサーバを変更済みの筈だが、そうではない場合はDNS設定画面のDNSレコードのリストの下にCloudflareから割り当てられたDNSサーバが2つ表示されるのでそれをコピーして現行のレジストラに登録することになる。(次へ)
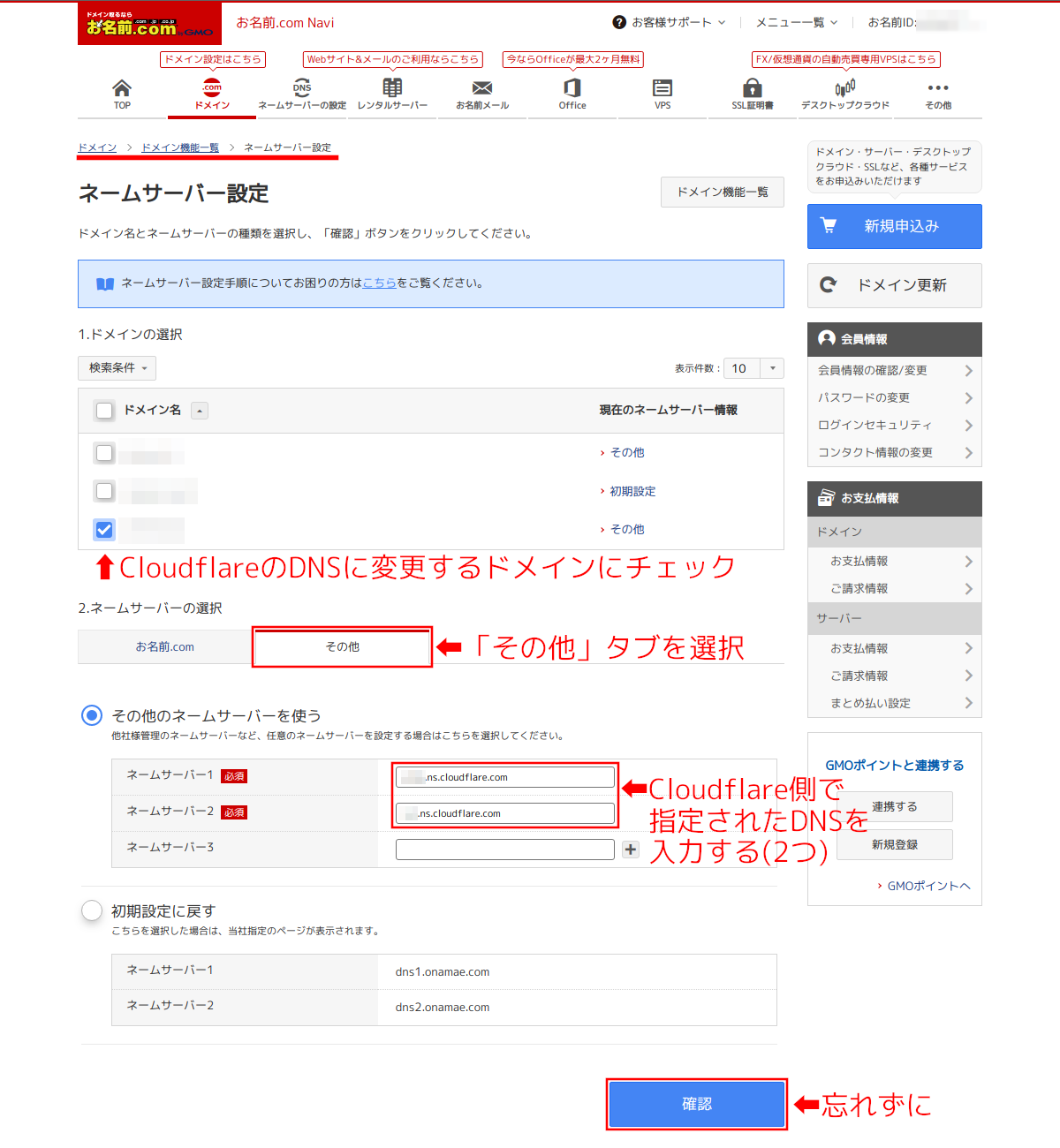
手順12:
現在利用中のレジストラ(ここでは仮に日本の「お名前.com」とする)でDNSサーバの登録を変更する。
上でCloudflareに登録したドメインを選択して、そのドメインに登録済みのDNSサーバを全て外して変わりにCloudflareのDNSサーバを登録するのだが、「お名前.com」の場合は現在のDNSを外すというのはなくて「ネームサーバーの選択」で「その他」を選択して「その他のネームサーバーを使う」の欄のネームサーバー1とネームサーバー2にCloudflareのDNSサーバを入力する。指定された2つ以外のDNSサーバは登録してはダメ。
最後に右下の「確認」をクリック。(忘れやすいので注意)
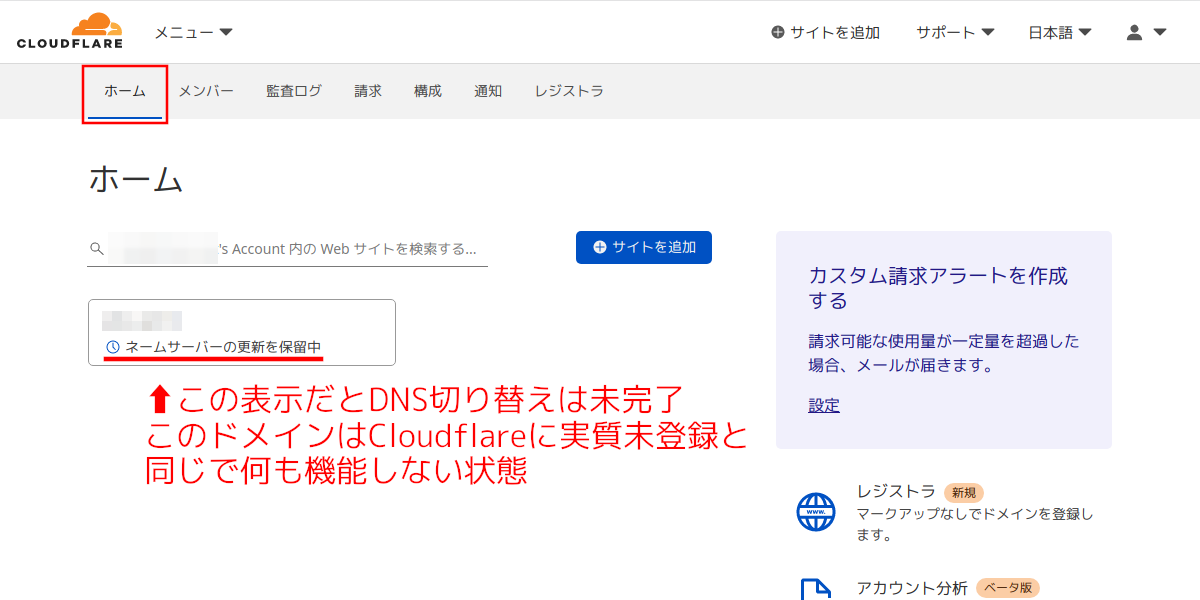
手順13:
(レジストラでのDNSサーバの変更は設定後にそれが反映されるまで時間がかかることがあります)
Cloudflareの側では自動的にDNSサーバを確認することを繰り返していて、現行のレジストラでDNSサーバの登録を変更した後にそれが適用されると検知される。それまではCloudflareのメイン画面ではこのような画面。
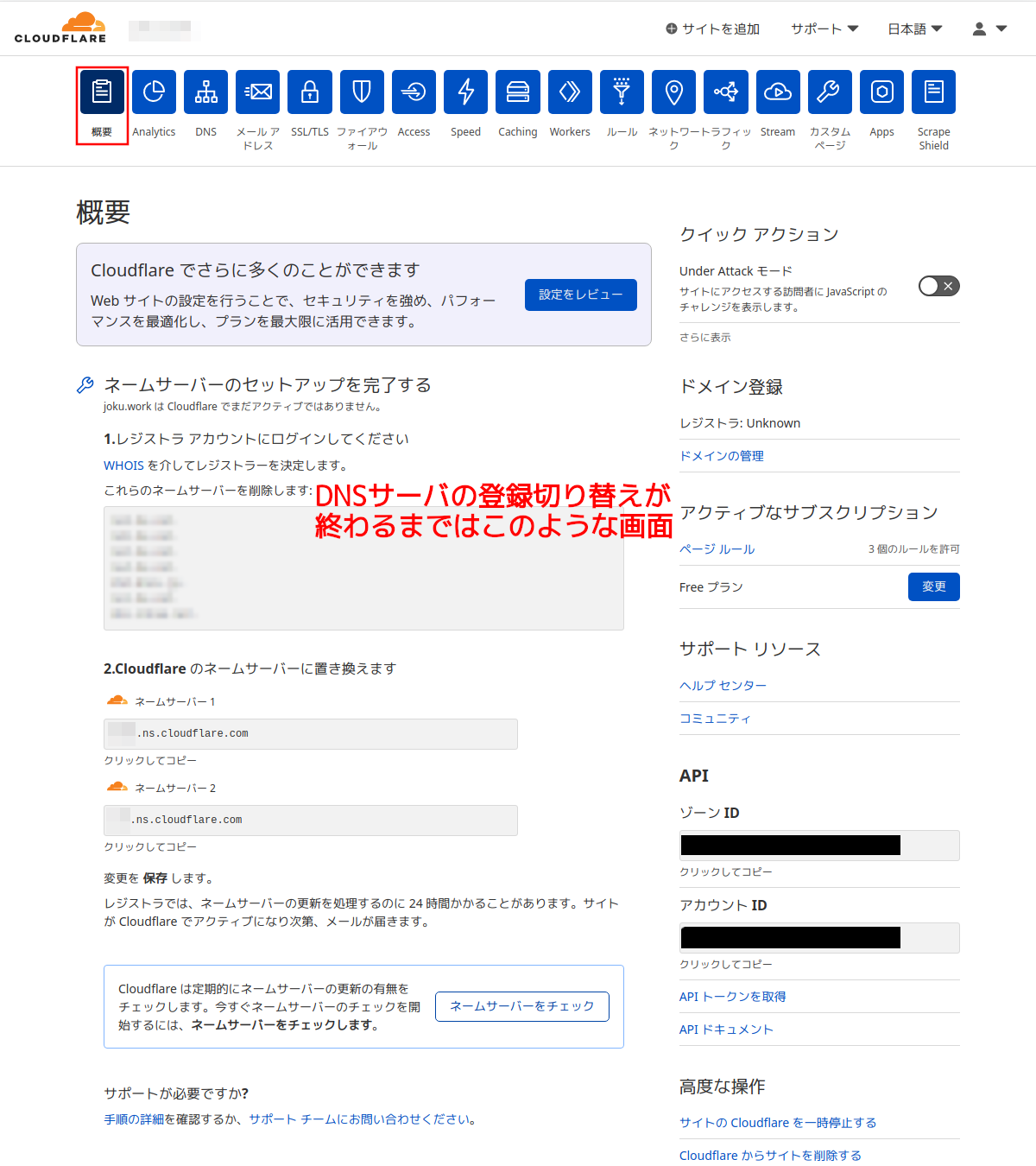
手順14:
1つ前の画面でドメイン名の枠をクリックするとこのような画面になる。
レジストラでDNSサーバの変更が完了するまでは現在レジストラに登録されているDNSサーバを外してCloudflareのDNSのサーバを登録しろという内容が表示される。
この画面が表示される間は次に進めないので暫く待って再びCloudflareのトップ画面を表示する。ドメインの欄が「ネームサーバーの更新を保留中」だと未完了。
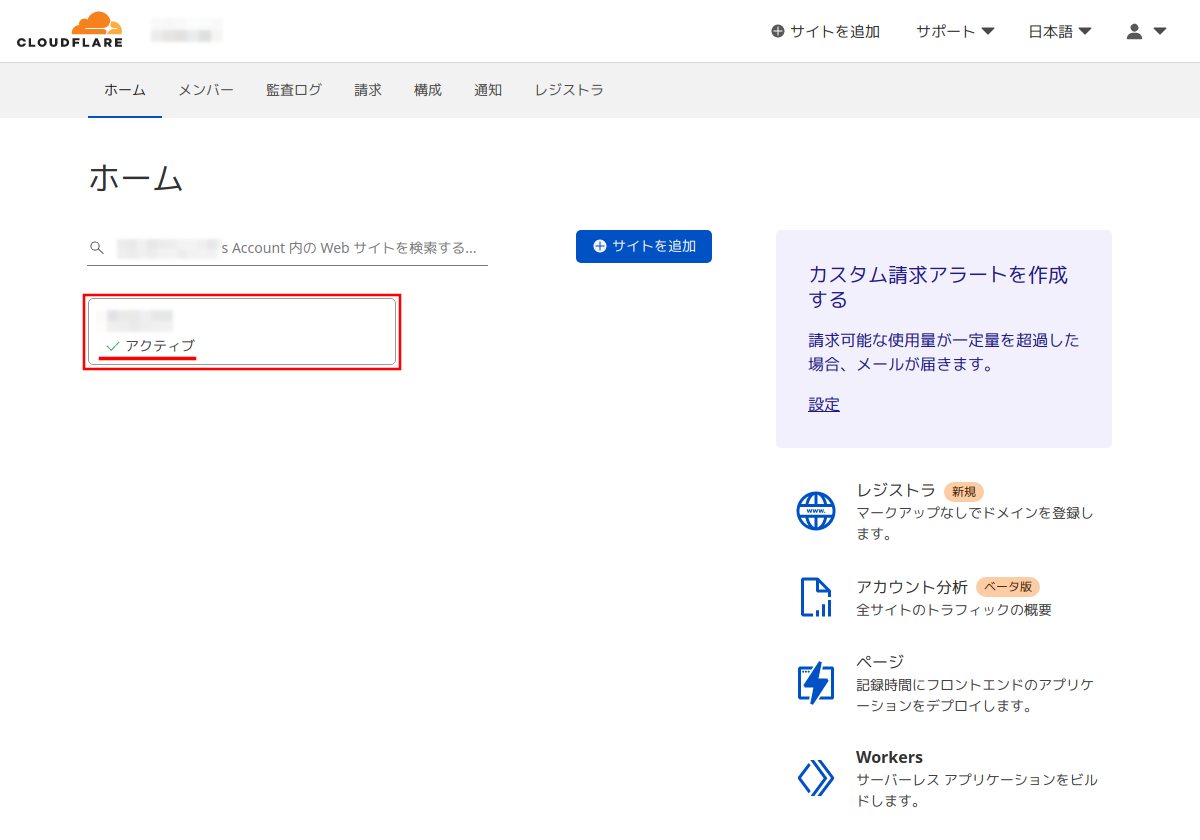
手順15:
ドメインの欄が「アクティブ」になればDNSサーバの登録変更が完了。
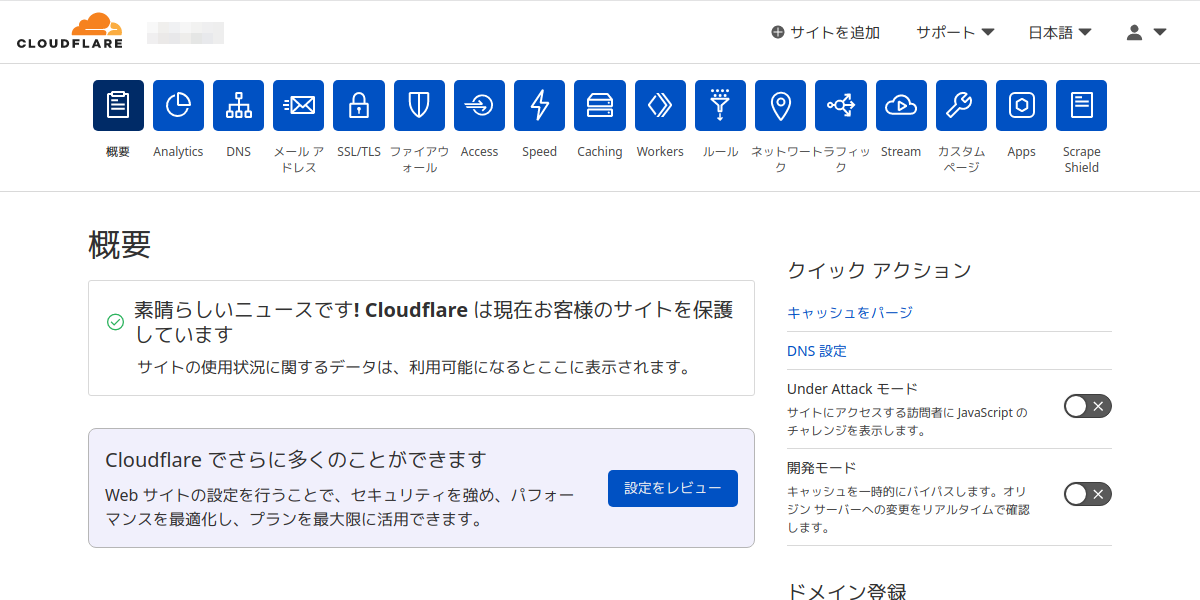
手順16:
1つ前(手順15)でドメインの枠をクリックすると「素晴らしいニュースです!Cloudflareでは現在のお客様のサイトを保護しています」に変わっている。
ここまでで、慣れていない人にとってはようやくDNSサーバの切り替えが終了。慣れてる人にとってはウェブ上でチョイチョイっと変更で済むので難しくはないよね。
次がメインとなるドメインの移管。こちらも他所でドメインの移管ってのをやったことがある人にとっては(大枠でやり方は変わらないので)難しくはないが、やったことが無い人にとっては根本的に何をどうすればよいのか判らないところ。
ドメインの移管
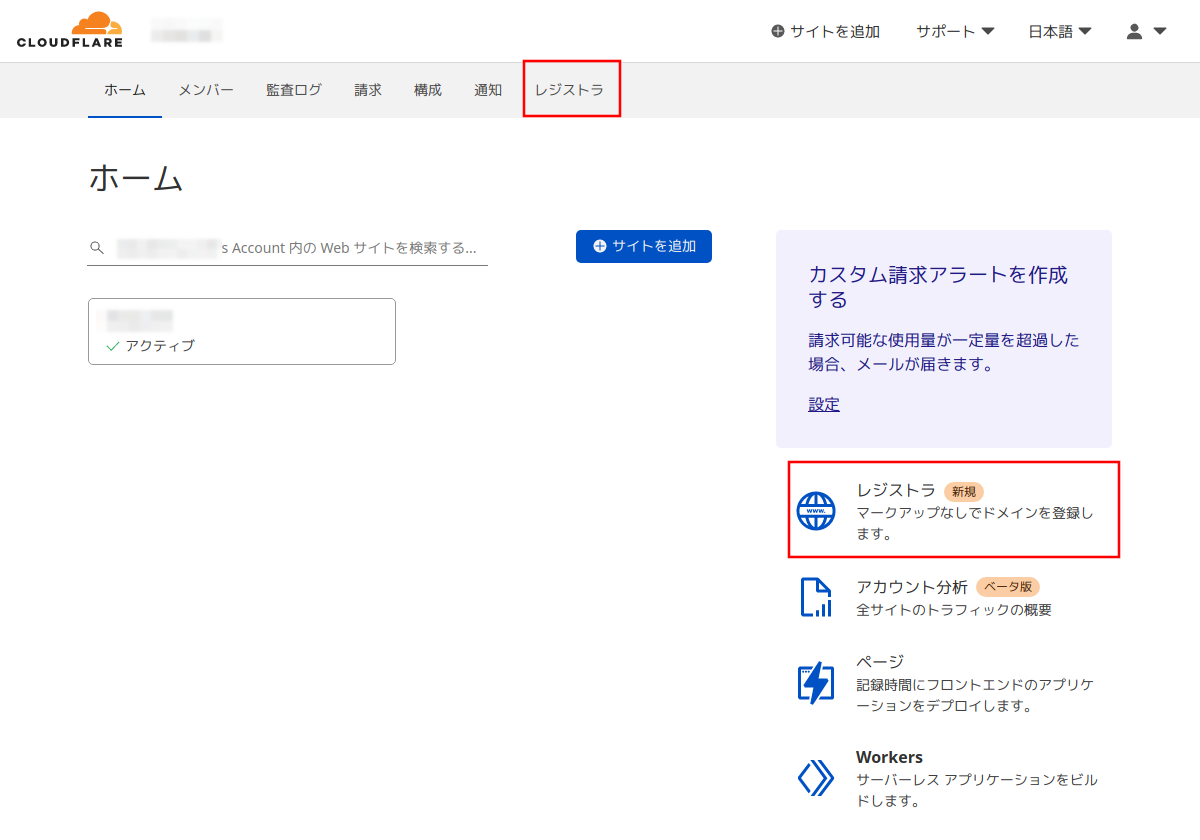
手順17:
Cloudflareにログインした状態のトップページで「レジストラ」をクリック。画像の2つの赤枠のどちらでも。
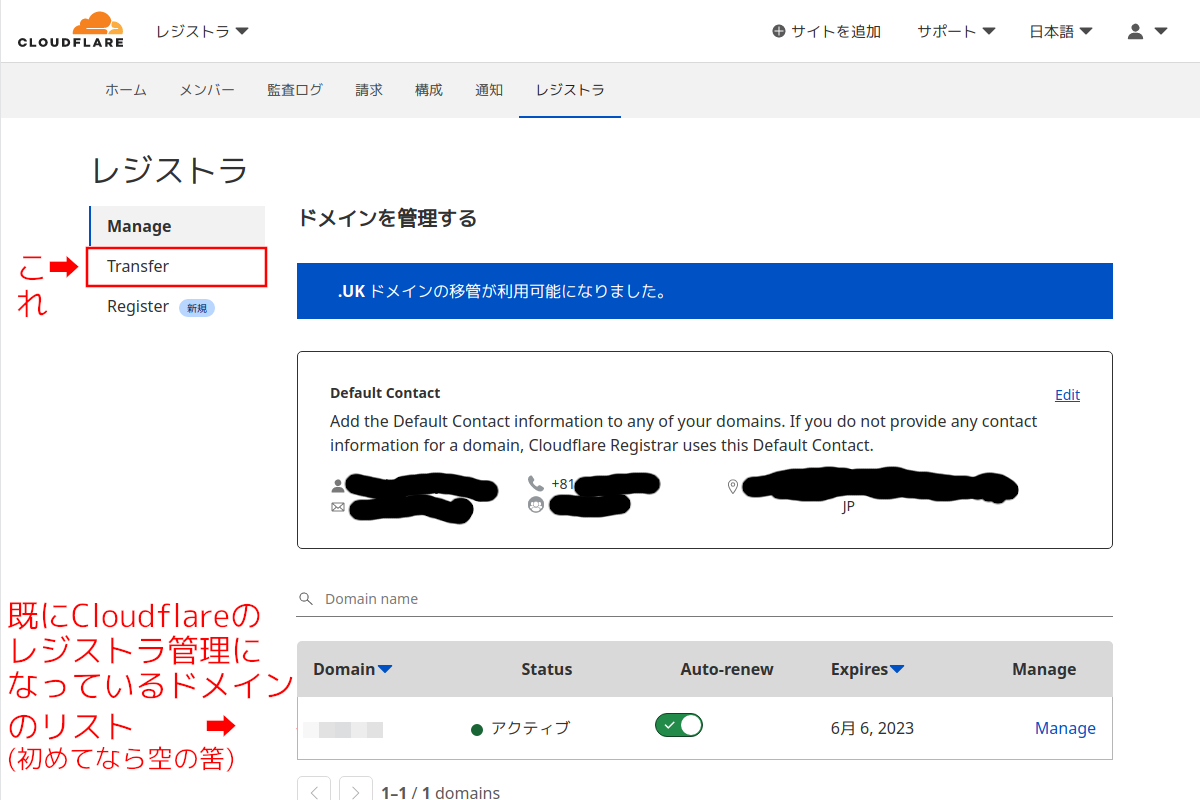
手順18:
レジストラ画面の左列のメニューで「Transfer」(移管)をクリックする。
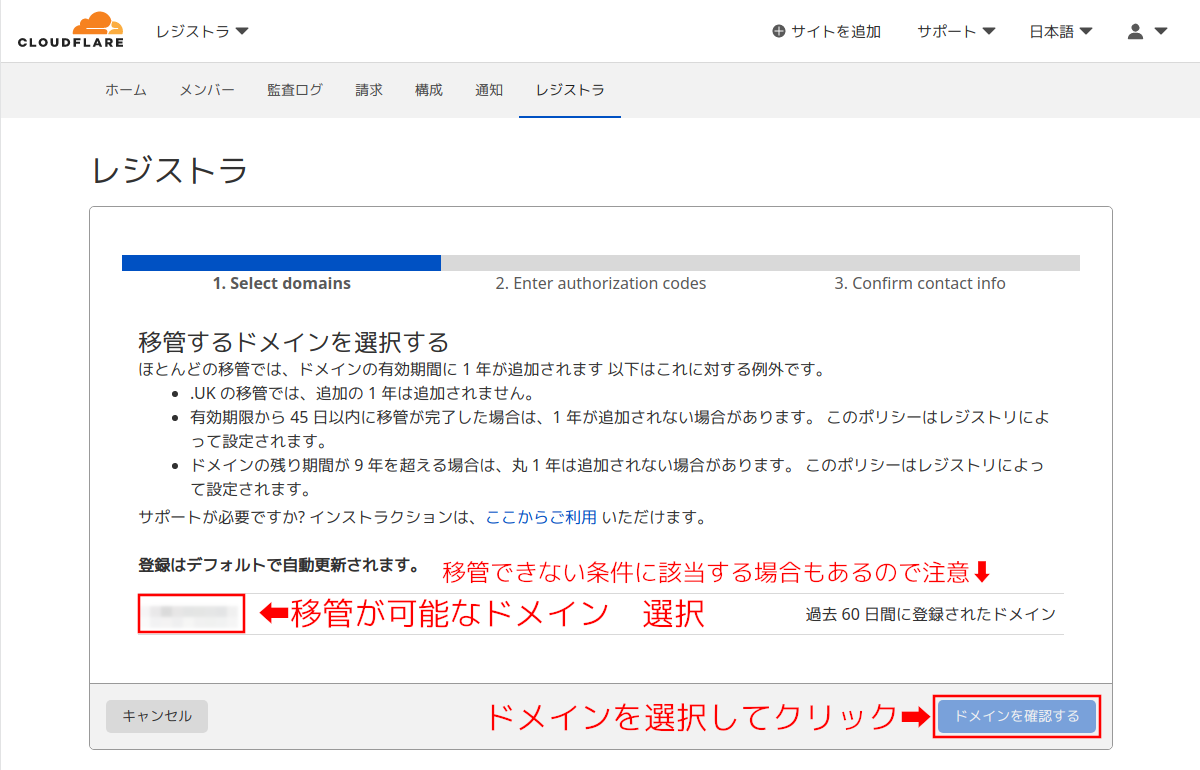
手順19:
Cloudflareに登録済み(DNSサーバの移転済み)のドメインが表示される。
画像では取得から間がないドメインが表示されていて、これは移管ができないため「ドメインを確認する」ボタンが押せない状態で次に進めない。
また、Cloudflareのレジストラで取扱いのできないTLDがある。この場合は、そもそもこの画面に移管が可能なドメインとして表示されない。たとえば.jpドメインはCloudflareで取扱のないTLDなのでCloudflareでは新規取得はもちろん移管もできない。Cloudflareレジストラで取扱いできるTLDのリスト
DNSサーバの移転やプロクシ機能は関係ないのでCloudflareレジストラで取扱いのないTLDでも利用できます。
とにかく、移管したいドメインを選択して右下の「ドメインを確認する」をクリック。
今回は例示できる移管可能なドメインの余りが無くこの後幾つかの画面のスクショが撮れていません。スミマセン。
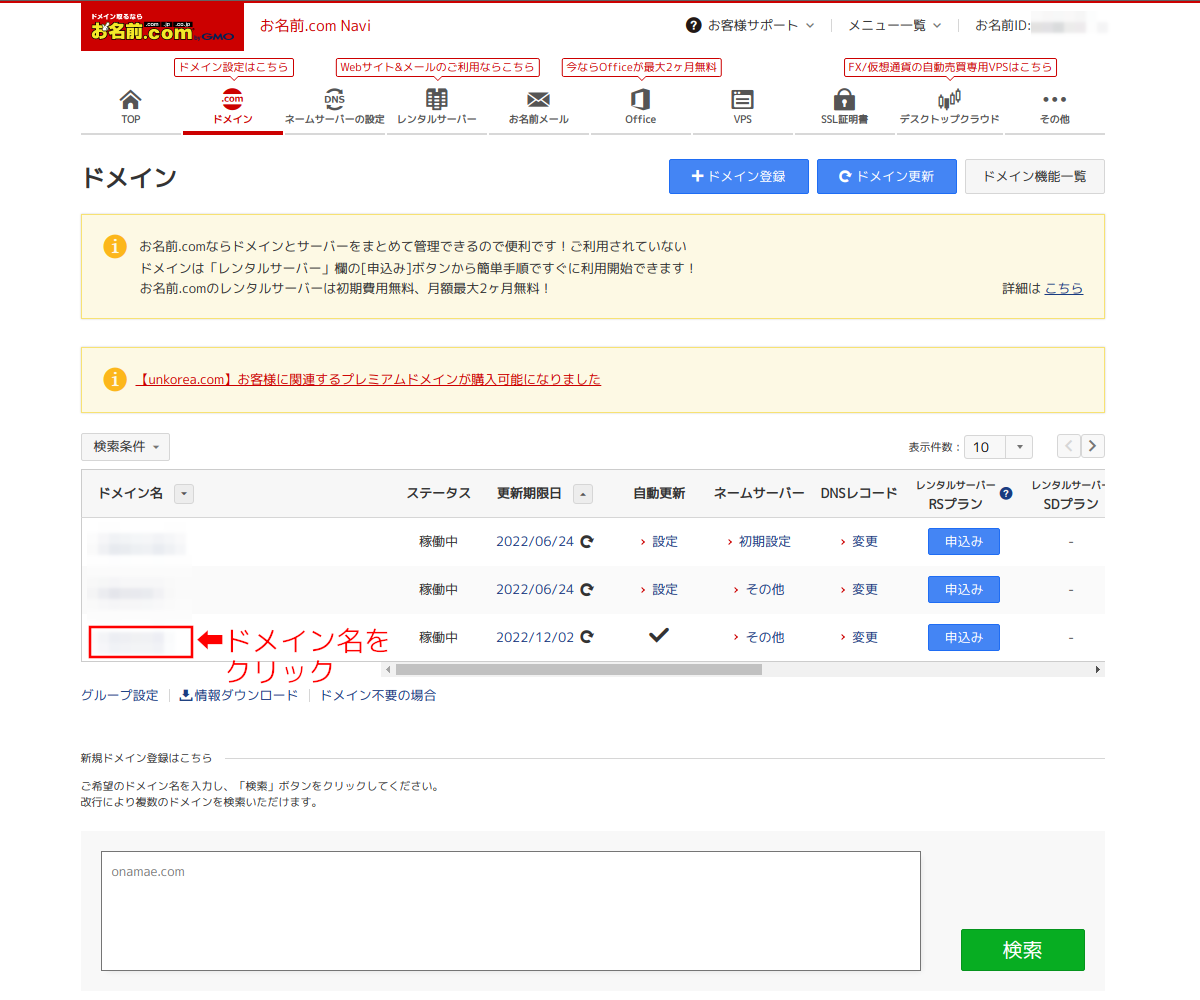
手順20:
Cloudflareのブラウザ画面はそのままにして、別のブラウザ窓を開き、移管元(引っ越し前の)レジストラの管理画面(ここでは「お名前.com」)を開く。お名前.comでは「お名前.com Navi」にログインして「ドメイン」の画面を表示する。ドメイン一覧からCloudflareに移管させたい(DNSサーバ登録変更済みの)ドメイン名をクリックする。他のレジストラでも管理画面で同様にドメイン一覧から移管させたいドメインを選択する。
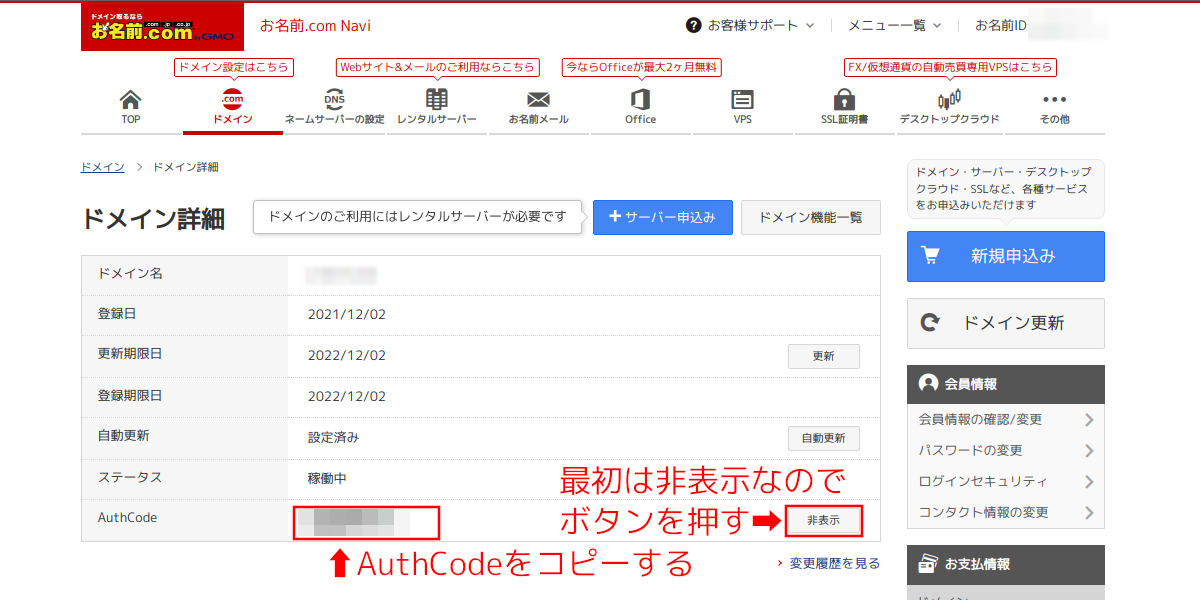
手順21:
「お名前.com Navi」ではドメインを選択して表示される「ドメイン詳細」の画面にAuthCodeが表示される。(デフォルト非表示なのでボタンで表示)
その文字列をコピーする(またはメモる)。
他所のレジストラでもドメインの詳細のような画面にAuthCodeが表示されるか移管関係の画面にAuthCodeを表示する機能がある筈。
画像無し:
また、移管元のレジストラ(お名前.comやその他のレジストラ)で移管を防止するためのロック機能をオンにしている場合はその機能をオフにする。
画像無し:
Cloudflareのブラウザに戻り、コピーしたAuthCodeをペーストまたは入力する。AuthCodeを利用してCloudflareレジストラが移管元のレジストラと移管の手続きを行う。これは、レジストラ間で行われるのでドメインオーナー(私達)はすることは殆ど無くて「移管の承認」(次)くらい。(Cloudflareレジストラではこのタイミングで支払いも)
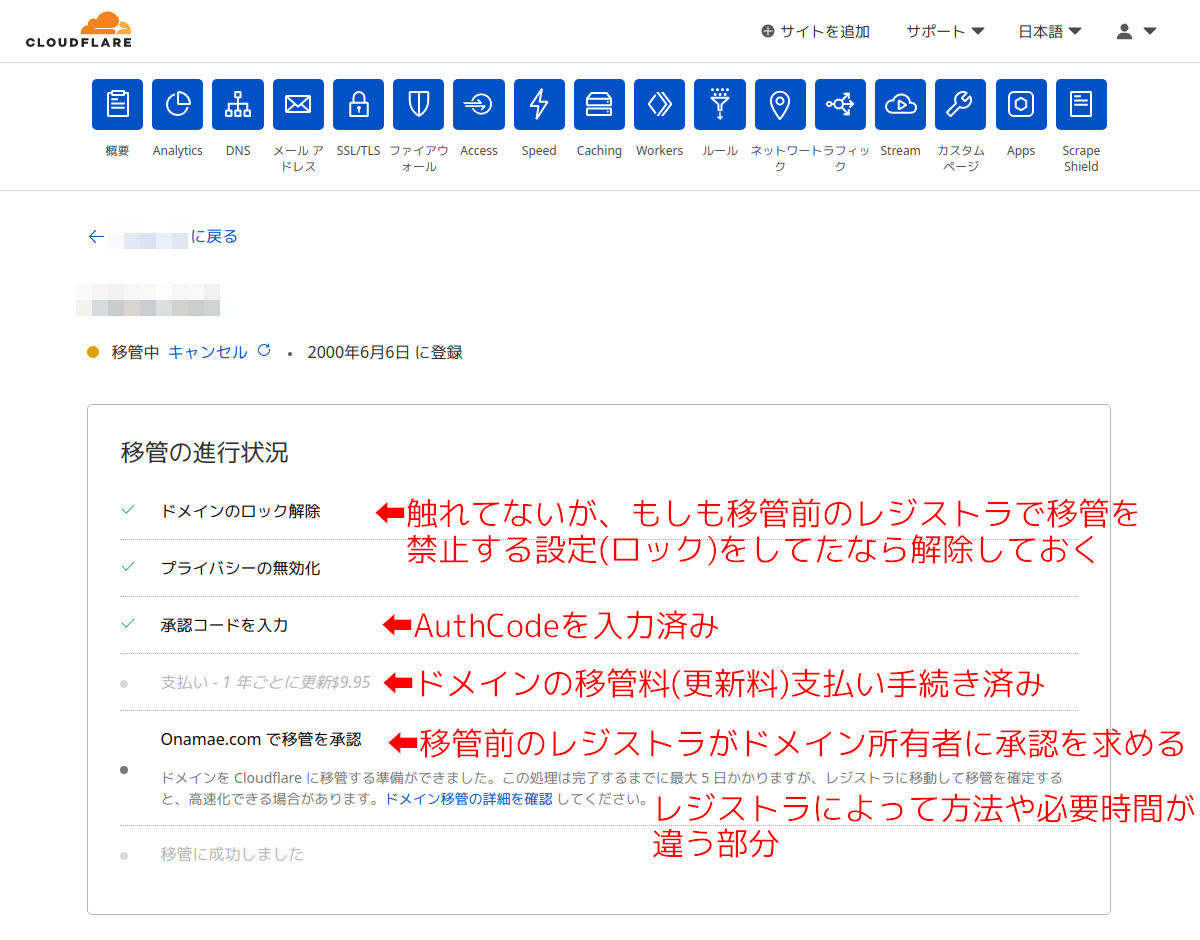
手順22:
AuthCodeを入力後、支払いの手続きを完了するとこの画面。
移管前のレジストラが移管手続きを行っている状態。ここで昔は数日を要することもあったが、どのレジストラも自動化されたのか最近は1時間かからないことが多い。
ただし、移管元のレジストラがドメインオーナーに「移管の申請が来ているが、その意志があるのか?」という確認を求めるようになっているので承認してやる必要がある。これは移管元のレジストラの管理画面で、或いはメールで確認を求められることが殆ど。
なのでメールの到着を待ち構え、メールが届いたらすぐに承認することがこの段階をすばやく終わらせるコツ。
もちろん、承認しないと進まないし、承認手続きの際に否認したら移管は失敗する。

手順23:
お名前.comの場合はこのような移管申請の確認を求めるメールが届く。
メール内にある承認リンクをクリックするとドメインオーナーによる移管の承認が行われたことになり移管の処理が進む。(数分から数時間でCloudflareにドメインの管理権限が渡って移管完了になる)
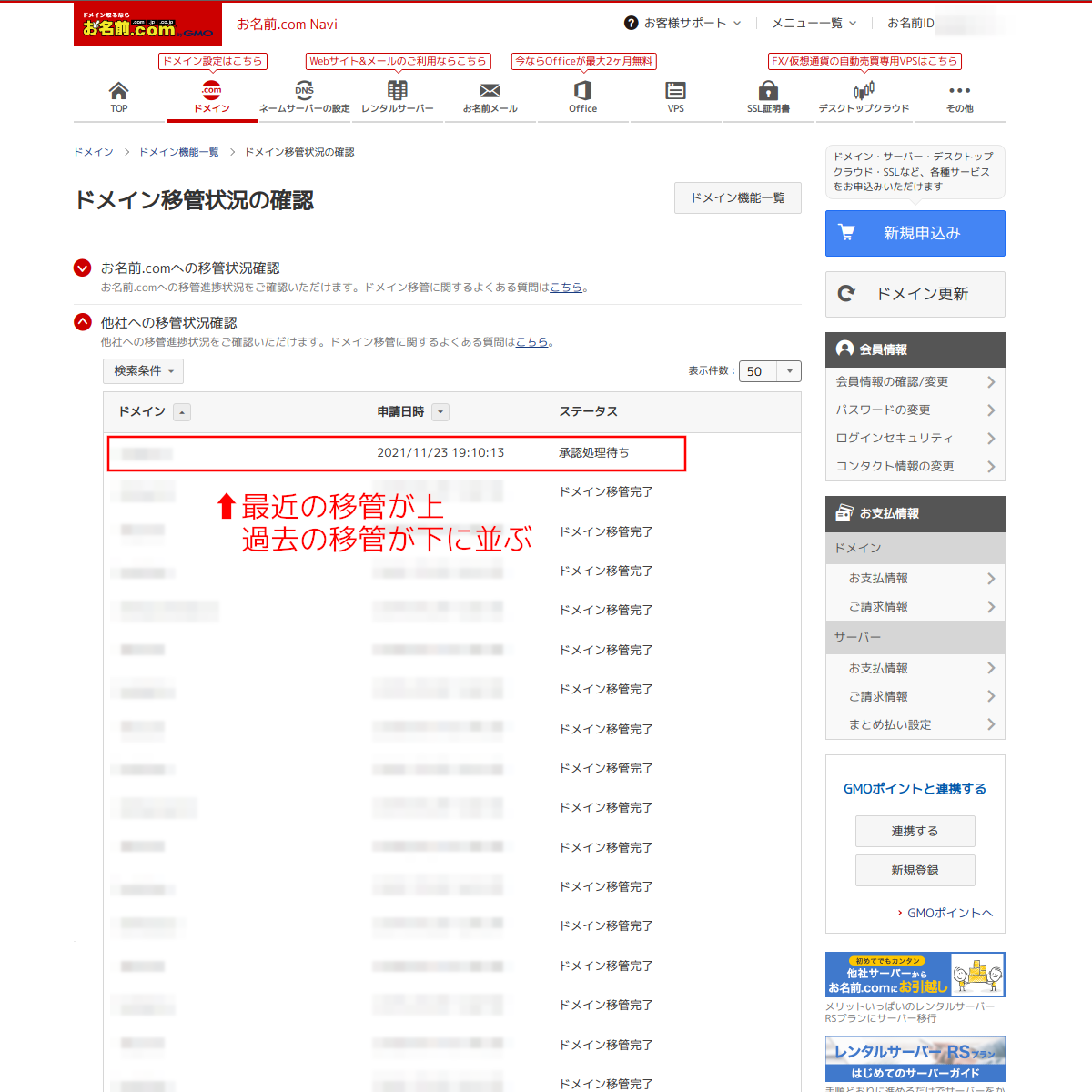
手順24:
移管元(引っ越し前)のレジストラでも移管の状況を確認できる。
画像は、メールの承認リンクを押して承認した直後くらいに撮ったスクショ。まだ承認処理が完了していない。
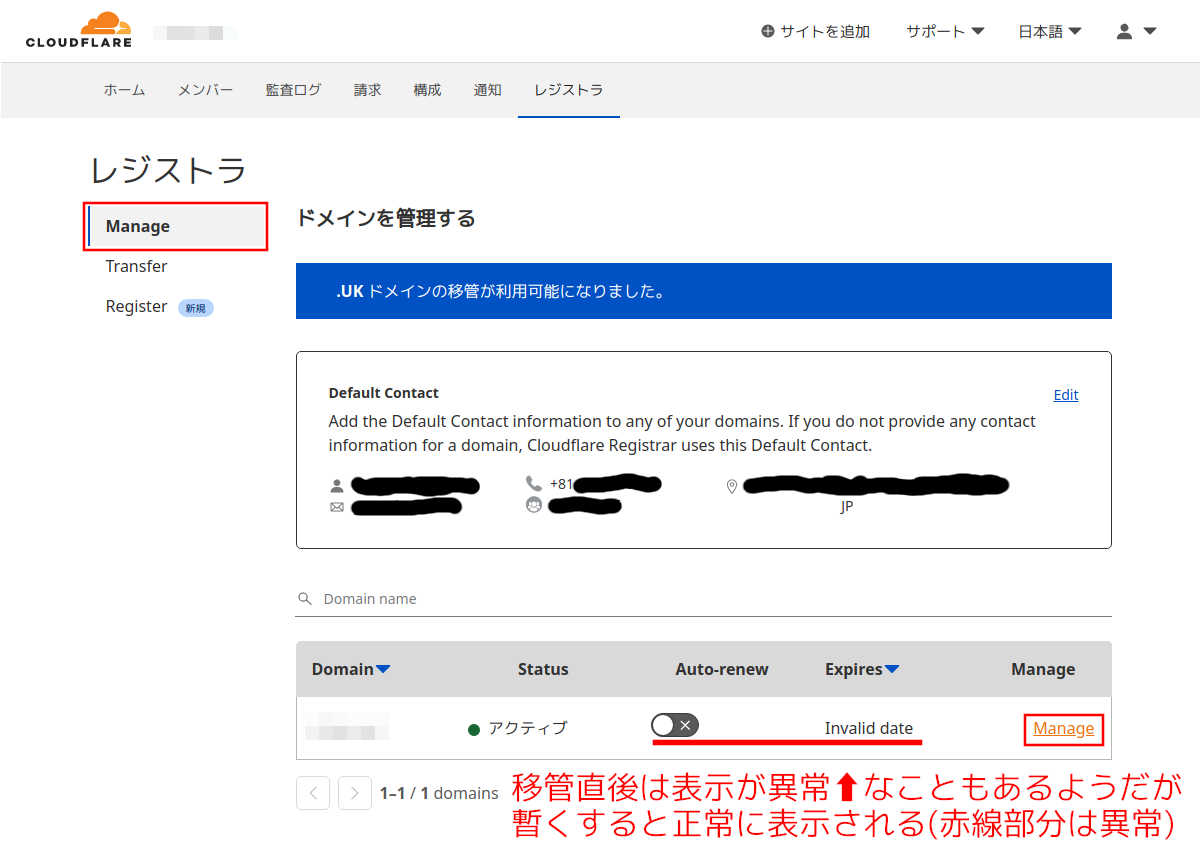
手順25:
Cloudflareレジストラの画面の左列で「Manage」で移管の完了を確認する。画像ではStatusは既に「アクティブ」になっているので一応移管しているようだが、Auto-renew (ドメイン年次自動更新)のスイッチがオフでExpiresに正しいドメインの期限が表示されずに「Invalid date」などと表示されているので完全には完了していなさそうな感じ。
一番右の「Manage」をクリック
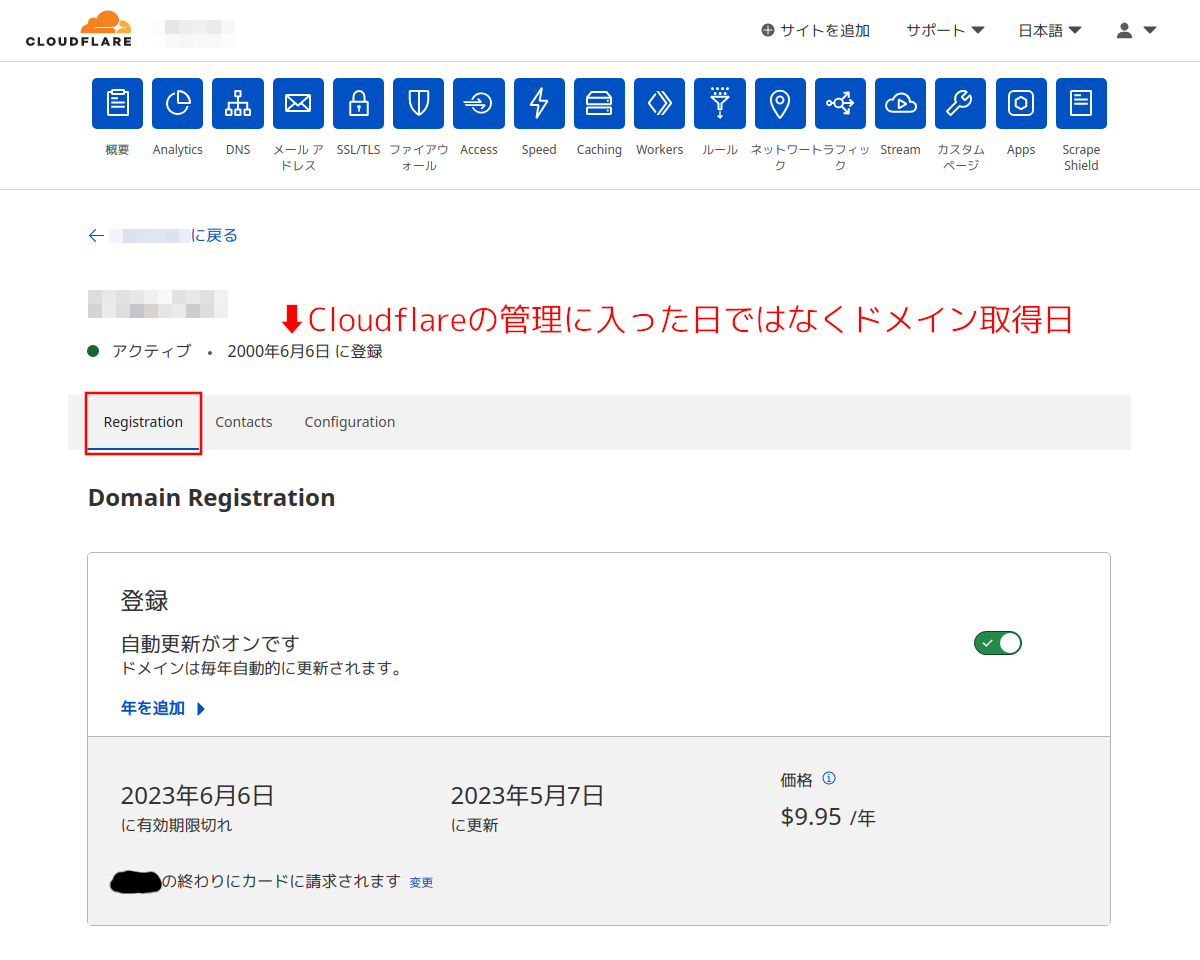
手順26:
数分後のスクショだが、「既に自動更新がオンです」になっていて「ドメインの有効期限」の日付も表示されている。移管は完全に完了した模様。
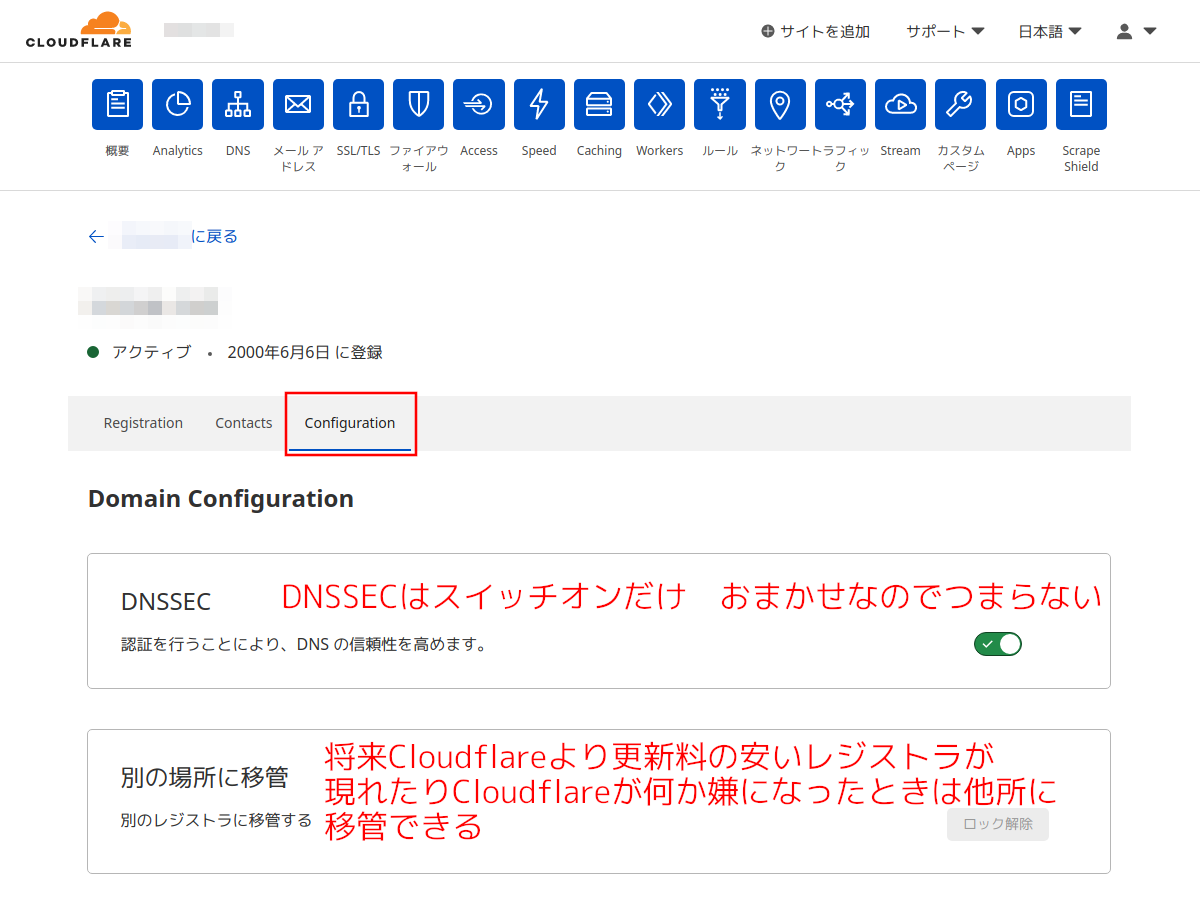
手順27:
「Configuration」タブを選択。
DNSSECのスイッチはオンにしたいところ。
また、今回は他所のレジストラからCloudflareレジストラに移管したが、将来また他所のレジストラに移管したいということになったときにはこの画面から移管させることが可能になるみたい。(まだ、移管したばかりで他所に移管させるためのロック解除のボタンが押せないためどのような画面が表示されるのかは不明。)
多くのドメインと多くのレジストラではドメインを移管する際にドメイン1年分の料金を支払うことになるが、その1年分の料金でドメインの有効期間が1年伸びることになるので実質的には移管のための費用は取られない。家賃でいえば家賃1ヶ月分の更新料を支払うとその月の家賃が免除されるようなもの。なので手間さえ惜しまなければドメインの移管というのは「損」はない。どんどん安いレジストラまたは信用できる良いレジストラに移管させてしまえば良いと思う。無駄に更新料の高くて使い勝手の良くないレジストラを使い続ける必要はない筈。