Filebeatで幾つかのログを読ませてKibanaで可視化するまでの記事を書いたが、「がとらぼ」の中の人の性格もあってとにかく「雑」これにつきる。
そこで、今回は少し丁寧にLogstashで加工してみる。
今回統計ログを取得するNTPサーバは以前にNanoPi NEOとGPSモジュールで作ったやつ。OSはarmbian (debian: Linux)
NanoPi NEOストレージが信頼性ゼロのmicroSDカードなのでログを書きまくると速攻でぶっ壊れる可能性があるため注意が必要。
NTPサーバの設定
/etc/ntp.conf (統計ログ周りだけ)1 2 3 4 | statsdir /tmp/
statistics loopstats peerstats
filegen loopstats file loopstats type day enable
filegen peerstats file peerstats type day enable
|
まともな機材でストレージに余裕があるなら/var/log, /var/log/ntpあたりを指定すれば良いはず。
出力する統計ログはloopstatsとpeerstatsの2つだけとする。
2つのログは日次で日付別ファイルに移すこととする。つまりloopstatsであれば日付が変わったら /tmp/loopstatsが /tmp/loopstats.20180320などの日付別ファイルに移動され、新しい/tmp/loopstatsが出来てそこに統計ログが追記される。ただし、UTCなので日付変更処理は日本時間だと午前9時。
tmpfsの場合は容量が非常に限られるということで、cronでloopstats.20* peerstats.20* を日次で削除するのが望ましい。tmpfsはシステムを再起動したら消えてしまうが、今回は統計ログをelasticsearchに送るので問題ないはず。
Filebeatの設定
/etc/filebeat.yml1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | filebeat.prospectors:
# loopstats
- type: log
enabled: true
paths:
- /tmp/loopstats
fields:
type: loopstats
#peerstats
- type: log
enabled: true
paths:
- /tmp/peerstats
fields:
type: peerstats
filebeat.config.modules:
path: ${path.config}/beats/file_*.yml #今回も使わない
reload.enabled: false
reload.period: 60s
output.logstash:
hosts: ["192.168.2.24:5044"] #出力先はLogstash 本番用ポート5044
logging.level: debug
logging.selectors: ["*"]
logging.to_syslog: false
logging.to_files: true
logging.files:
path: /var/log
name: filebeat.log
|
# service ntp restart # service filebeat restart
統計ログの確認
/tmp/peerstats1 2 3 4 5 | 58197 5594.402 2001:3a0:0:2006::87:123 9344 0.001557429 0.011391145 0.002156915 0.000110542
58197 5601.391 127.127.20.0 968a 0.000422118 0.000000000 0.000301040 0.000840302
58197 5602.391 127.127.22.0 973a 0.000003027 0.000000000 0.000234952 0.000009770
58197 5617.391 127.127.20.0 968a 0.000395065 0.000000000 0.000270868 0.000847744
58197 5618.391 127.127.22.0 973a -0.000000919 0.000000000 0.000234496 0.000008626
|
- 修正ユリウス日
- 日付変更からの秒数(UTCなので日本時間では9:00からの秒数)
- 時刻ソース
- ステータス (16進)
- 時間のオフセット(秒)
- 遅延(秒)
- 分散(秒)
- RMSジッタ,スキュー (秒)
時刻ソースはNTPサーバを参照していればIPアドレスだが、127.127.*.*はIPアドレスではなくリファレンスクロックアドレス。 例えば127.127.20.0ならGPSのMNEA、127.127.22.0ならGPSのPPSなど。 /tmp/loopstats
1 2 3 4 5 | 58197 5666.391 0.000001450 -31.896 0.000025471 0.003549 4
58197 5682.391 -0.000004722 -31.897 0.000021987 0.003345 4
58197 5698.391 0.000004691 -31.896 0.000009533 0.003155 4
58197 5714.391 -0.000007993 -31.966 0.000022231 0.024948 4
58197 5730.391 -0.000006354 -31.967 0.000020404 0.023343 4
|
- 修正ユリウス日
- 日付変更からの秒数(UTCなので日本時間では9:00からの秒数)
- 時間のオフセット(秒)
- ドリフト, 周波数のオフセット(PPM)
- RMS ジッタ(秒)
- RMS 周波数ジッタ(PPM)
- インターバル(log2秒)
Logstashの設定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | input {
beats {
port => 5044
}
}
filter {
if [fields][type] == "hoge" {
# 他のフィルタ 省略
}
if [fields][type] == "peerstats" {
grok {
patterns_dir => ["/usr/local/etc/logstash/patterns"]
match => {"message" => "%{NUMBER:[temp]julian} %{NUMBER:[temp]pastsec} %{IP:[ntp]source} %{DATA} %{NUMBER:[temp]offset} %{NUMBER:[temp]delay} %{NUMBER:[temp]dispersion} %{NUMBER:[temp]skew}"}
remove_field => ["message", "beat", "source", "offset", "input"]
}
ruby {
init => "require 'bigdecimal'"
code => "
mjd = event.get('[temp]julian').to_i
psec = event.get('[temp]pastsec').to_i
ut = (mjd - 40587) * 86400 + psec
event.set('[temp]unixtime', ut)
event.set('[ntp]offset', BigDecimal(event.get('[temp]offset')) * 1000)
event.set('[ntp]delay', BigDecimal(event.get('[temp]delay')) * 1000)
event.set('[ntp]dispersion', BigDecimal(event.get('[temp]dispersion')) * 1000)
event.set('[ntp]skew', BigDecimal(event.get('[temp]skew')) * 1000)
"
}
date {
match => ["[temp]unixtime", "UNIX"]
remove_field => ["temp", "tags"]
}
}
if [fields][type] == "loopstats" {
grok {
patterns_dir => ["/usr/local/etc/logstash/patterns"]
match => {"message" => "%{NUMBER:[temp]julian} %{NUMBER:[temp]pastsec} %{NUMBER:[temp]offset} %{NUMBER:[temp]drift} %{NUMBER:[temp]jitter} %{NUMBER:[temp]freqjit} %{NUMBER}"}
remove_field => ["message", "beat", "source", "offset", "input"]
}
ruby {
init => "require 'bigdecimal'"
code => "
mjd = event.get('[temp]julian').to_i
psec = event.get('[temp]pastsec').to_i
ut = (mjd - 40587) * 86400 + psec
event.set('[temp]unixtime', ut)
event.set('[ntp]offset', BigDecimal(event.get('[temp]offset')) * 1000)
event.set('[ntp]drift', BigDecimal(event.get('[temp]drift')))
event.set('[ntp]jitter', BigDecimal(event.get('[temp]jitter')) * 1000)
event.set('[ntp]freqjit', BigDecimal(event.get('[temp]freqjit')) * 1000)
"
}
date {
match => ["[temp]unixtime", "UNIX"]
remove_field => ["temp", "tags"]
}
}
}
output {
elasticsearch { hosts => [ "localhost:9200" ] }
}
|
NTPサーバの統計ログは出力日時が修正ユリウス日(MJD)という殆ど目にしないものと、UTCで日付が変わってからの秒数。こういうの困るよね。
でも、珍しくやる気になったので、このログに記録されている日時をTimeStampとして使いたいと思う。修正ユリウス日と秒数ということなので計算してUnixtimeにしてやれば良さげ。
matchでログから切り分けた修正ユリウス日と秒数は「数値に見える文字列」なのでhoge.to_iで数値に変換してから使う。
Unixtimeは1970年1月1日がエポック。その日は修正ユリウス日で40587。
修正ユリウス日から40587を引いたものに1日の秒数86400を掛ける。それに日付が変わってからの秒数を足す。それがUnixtime。これをLogstashのフィルタのdate{ }で読ませるとタイムスタンプになる。
NTPサーバのログはミリ秒とかPPBで良いと思うんだけど、何故か秒とかPPMとか大きめの単位で出力されるので小数点以下にゼロが並ぶ数値になっている。これをLogstashで数値として扱うために迂闊にconvertでFloat型に変えると困ったことになる。
そこで、rubyプラグインでBigDecimalに読ませる。matchで切り分けした「数値に見える文字列」をそのまま読ませて大丈夫(というか文字列専用)なので都合も良い。さらに幾つかの値は1000を掛けて単位を変更する。
計算した数値は「数値に見える文字列」ではなくなっているので型変換は不要。
また、elasticsearchのタイムスタンプもUTCなのでタイムゾーンによる差分計算も不要。
これでLogstashからelasticsearchに送信されるデータは以下のようになる。
peerstatsの出力例1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | {
"fields": {
"type": "peerstats"
},
"@timestamp": "2018-03-20T05:01:54.000Z",
"host": "hoge.localnet",
"@version": "1",
"ntp": {
"delay": 0,
"dispersion": 0.234296,
"skew": 0.007733,
"offset": -0.007931,
"source": "127.127.22.0"
},
"prospector": {
"type": "log"
}
}
|
loopstatsの出力例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | {
"fields": {
"type": "loopstats"
},
"@timestamp": "2018-03-20T04:56:50.000Z",
"host": "hoge.localnet",
"@version": "1",
"ntp": {
"jitter": 0.022946,
"drift": -31.98,
"freqjit": 8.763,
"offset": -0.002991
},
"prospector": {
"type": "log"
}
}
|
Kibanaで可視化
例によってフィールドが追加されたらインデックスを更新する。Kibanaの左列メニューの (Management)からIndex Patternsを選択し、右上の (Refresh)を押す。
peerstatsのNMEAをTimelionでグラフ化するならこんな感じ。1 2 3 4 | .es(q='host:hoge.localnet AND fields.type:peerstats AND ntp.source:127.127.20.0', metric='max:ntp.skew').lines(width=1).label('skew ms'),
.es(q='host:hoge.localnet AND fields.type:peerstats AND ntp.source:127.127.20.0', metric='max:ntp.offset').lines(width=1).label('offset ms'),
.es(q='host:hoge.localnet AND fields.type:peerstats AND ntp.source:127.127.20.0', metric='max:ntp.delay').lines(width=1).label('delay ms'),
.es(q='host:hoge.localnet AND fields.type:peerstats AND ntp.source:127.127.20.0', metric='max:ntp.dispersion').lines(width=1).label('dispersion ms')
|
一応、時刻ソース別で項目を並べるんじゃなくて項目別にして時刻ソースを並べるべきじゃねという意見もあるかというのは認識している。
peerstatsのNMEAをTimelionでグラフ化するならこんな感じ。1 2 3 4 | .es(q='host:hoge.localnet AND fields.type:loopstats', metric='max:ntp.jitter').lines(width=1).label('jitter ms ←').yaxis(1),
.es(q='host:hoge.localnet AND fields.type:loopstats', metric='max:ntp.offset').lines(width=1).label('offset ms ←').yaxis(1),
.es(q='host:hoge.localnet AND fields.type:loopstats', metric='max:ntp.drift').lines(width=1).label('drift ppm →').yaxis(2),
.es(q='host:hoge.localnet AND fields.type:loopstats', metric='max:ntp.freqjit').lines(width=1).label('freq Jitter ppb →').yaxis(2)
|
一応、左右の振り分けをしているが、気に入らなければ適当に変える。
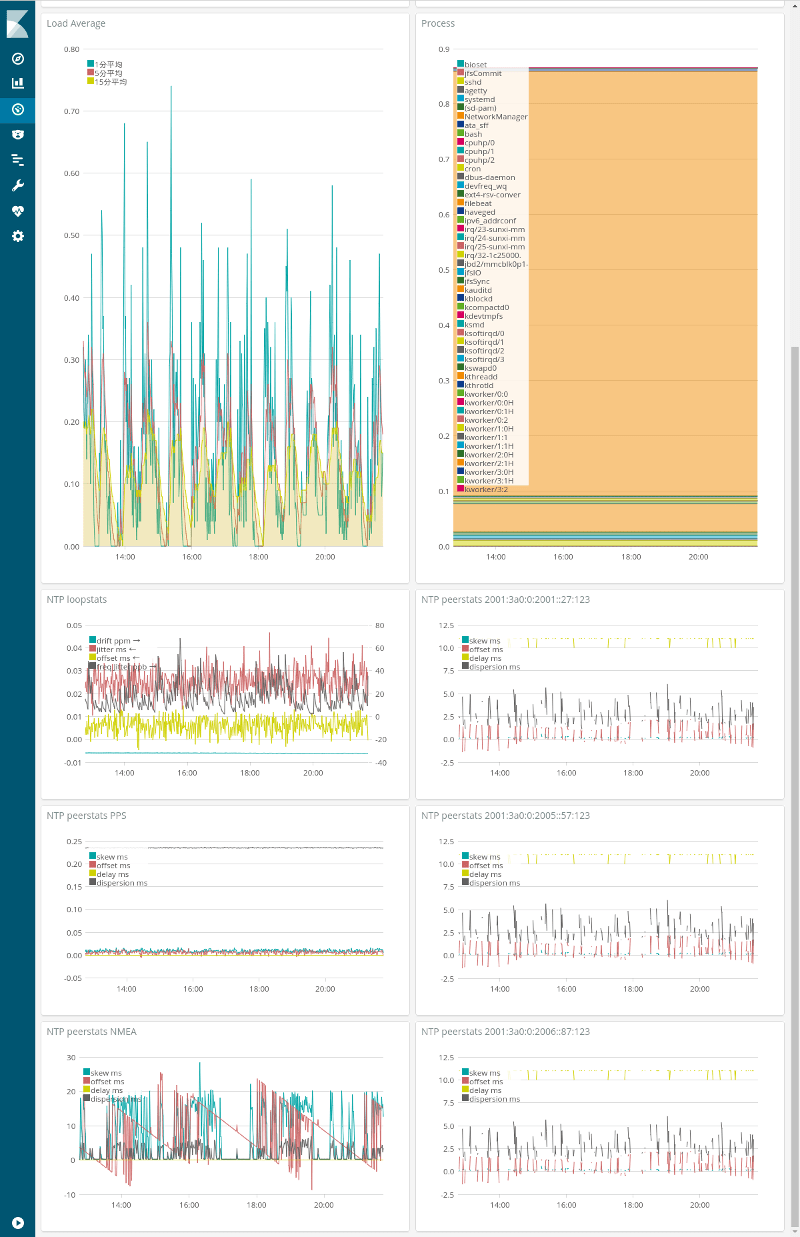
下半分の6つのグラフが今回の記事のNTP統計ログを可視化したもの。左列は上からloopstats、peerstatsのPPS, peerstatsのNMEA。右列はpeerstatsで外部のNTPサーバ(MFEEDのIPv6のサーバ3つ)。
左下のNMEAのグラフの赤線(offset)が規則正しいのこぎり状になっているのはNanoPi NEOにまともな時計が載っていないのにそれに同期しているからかと思われる。
右列の外部NTPサーバのグラフは3つ子かと思うほど同じだが、ネットワーク的に同じ(等距離)で全てMFEEDのサーバなので大幅に違うグラフになる方が変かなと。
と、いうことで、collectdに続いてfilebeatsでもNTPの統計情報を可視化できるようになった。でも、NTPの統計情報はcollectdでやる方が圧倒的に簡単かな・・・
関連記事:- ウェブ管理者の気まぐれ自作アクセス解析 ElasticsearchとKibanaを添えて
- TelegrafでElasticsearchにメトリクス送信+Kibanaで可視化 (後編)
- TelegrafでElasticsearchにメトリクス送信+Kibanaで可視化 (中編)
- TelegrafでElasticsearchにメトリクス送信+Kibanaで可視化 (前編)
- Metricbeatで収集したメトリクスデータをKibanaで可視化する
- Kibanaを操作する前にユーザーを作成する
- Metricbeat 8.6.0のインストールと設定
- Elastic Stack 8系をFreeBSDにインストール
- Elastic Stack 6.4.2への更新 FreeBSD ports用メモ
- WinlogbeatでWindowsイベントログを可視化 後編
- WinlogbeatでWindowsイベントログを可視化 中編
- WinlogbeatでWindowsイベントログを可視化 前編
- Elastic Stackを6.3.2に更新する
- Elastic Stackでシステム監視 Heartbeatで収集した死活情報をKibanaで可視化
- Elastic Stackでシステム監視 Heartbeatを使う準備
- Elastic Stackでシステム監視 FreeBSDのportsで6.2.3に更新
- ELK Stackでシステム監視 Filebeatで収集したVolumioのログから時系列の再生曲名リストを表示
- ELK Stackでシステム監視 Rspamd 1.7系のElasticsearchモジュールを試す
- ELK Stackでシステム監視 FilebeatでNTP統計ログ取得 Logstashで加工
- ELK Stackでシステム監視 FilebeatでRaspberry Pi Zero WのVolumio楽曲再生ランキング
- ELK Stackでシステム監視 MeticbeatでRaspberry Pi Zero WのVolumioを監視
- ELK Stackでシステム監視 FilebeatでFreeBSDのCPU温度取得+Kibanaグラフ化
- ELK Stackでシステム監視 FilebeatでFail2banのBan情報+地図表示
- ELK Stackでシステム監視 MetricbeatでNginxのステータス情報を取得+グラフ化
- ELK Stackでシステム監視 FreeBSDのportsでELK Stack6系をインストール
- ELK Stackでシステム監視 FreeBSDにMetricbeatをインストールしてみる
- ELK Stackでシステム監視 elasticsearchインデックスのスキーマが勝手に変わる対処 テンプレート作成
- NanoPi NEO2(arm64)用にFilebeatをビルド
- ELK Stackでシステム監視 kibanaでDNSサーバの情報表示
- ELK Stackでシステム監視 kibanaのTimelion,Timeseriesでグラフ作成