今日は世間的にはiPhoneの新機種が発表されて盛り上がっているところだろうが、そんなものには全く興味がないので独り喜びを噛みしめてることを書く。
LineageOS 16はAndroid 9 Pie世代のカスタムOS。
Zenfone 2 Laser (Z00L)のLineageOS 15.1が7月に公式リリースになったのだが、翌週に1度更新されてから何故か放置状態。で、非公式ビルドでは調子の良かったカメラが公式リリース版ではとんでもなくダメダメで使い物にならず、このまま更新されないようなら別のカスタムOSに乗り換えようかなと思っていたら先週になってXDAでLineageOS 16の非公式ビルドのα版?を公開する人が出た。「試しにビルドしてみたよ」レベルで実用に程遠いのかと思ったら、現状で動かないのはBluetoothとVoLTEで着信音が無い(通話も音声無し?) No In-call Audioって書いてある。それと、使用面ではあまり問題ではないがSELinuxがpermissiveという状態。最後のはLineageOS 15.1でも最初は同じだったよね。
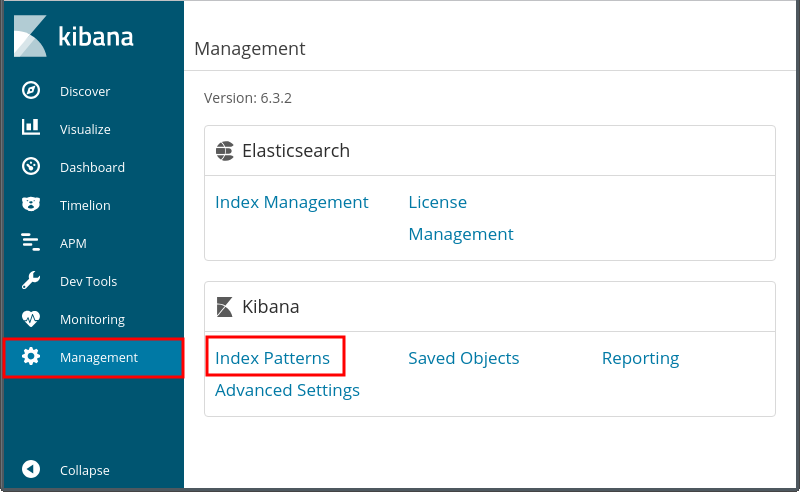
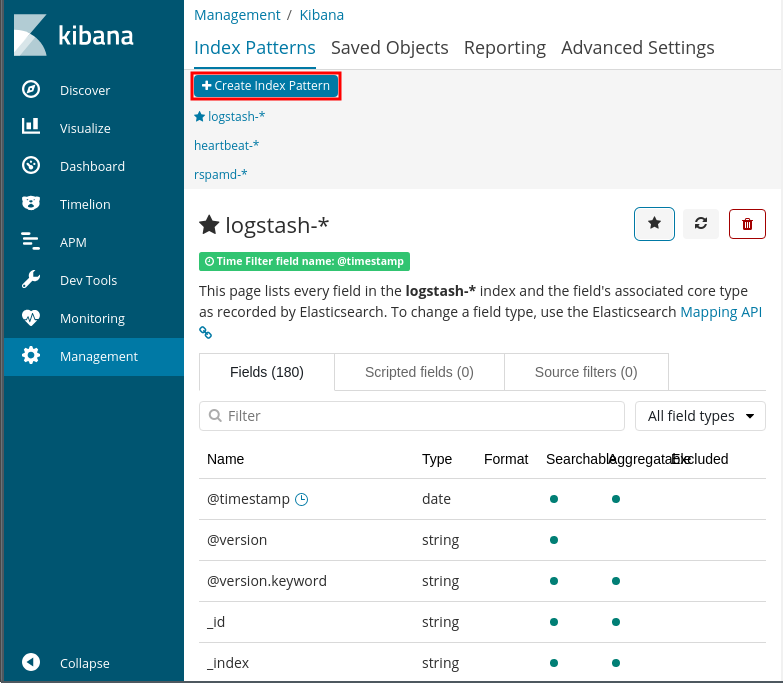
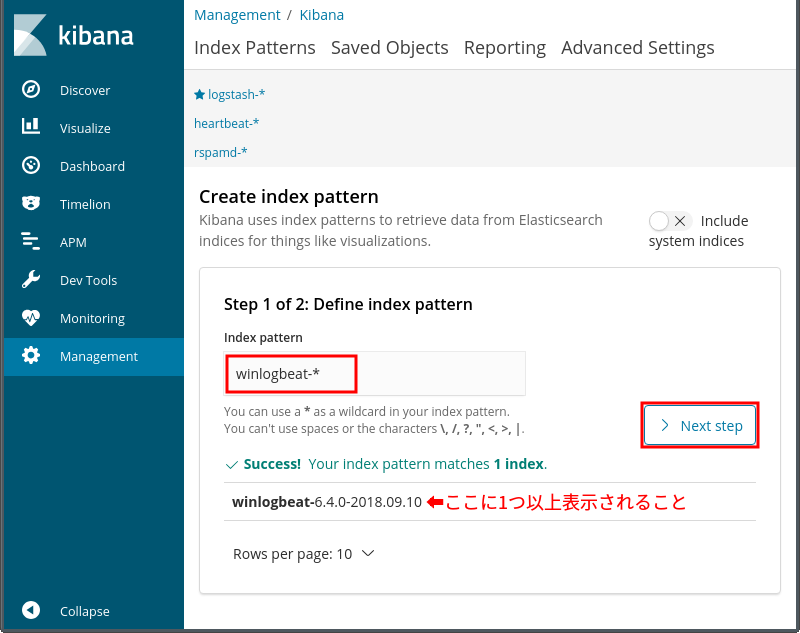
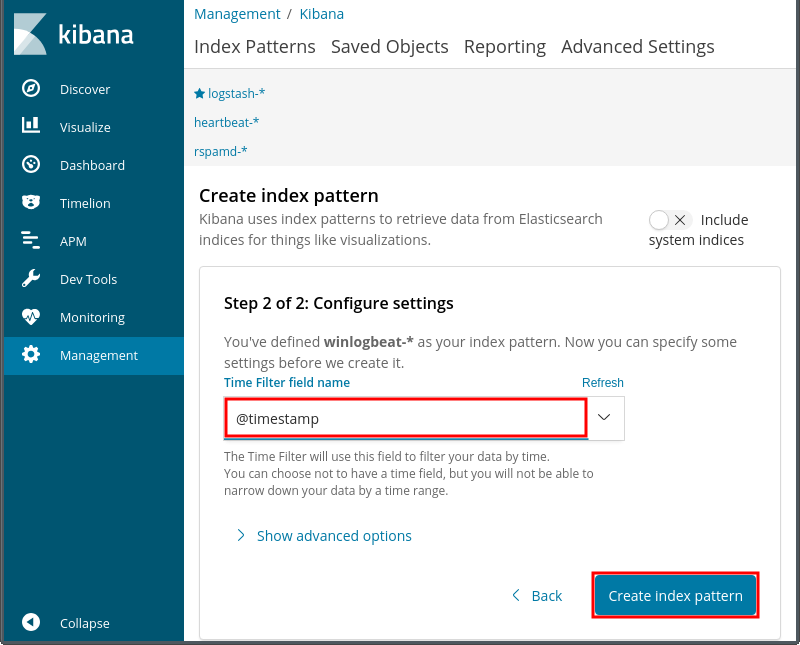
用意するもの
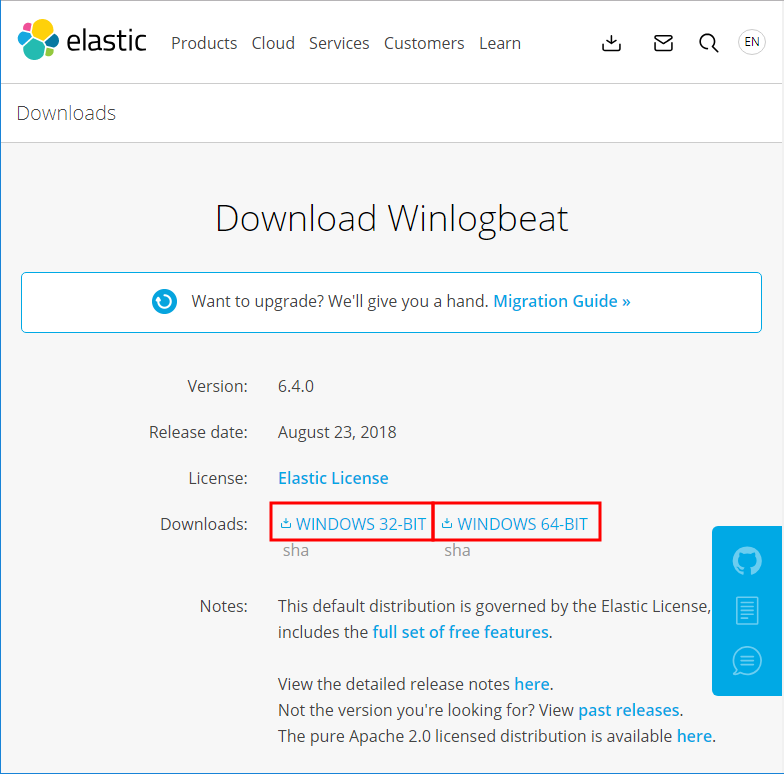
OSのイメージファイル
XDAのZenfone 2 Laser Z00L/Z00T用LineageOS 16のスレッド の最初の書き込みにダウンロードリンクがあるのでそこからOSのイメージファイルを貰ってくる。
OpenGapps
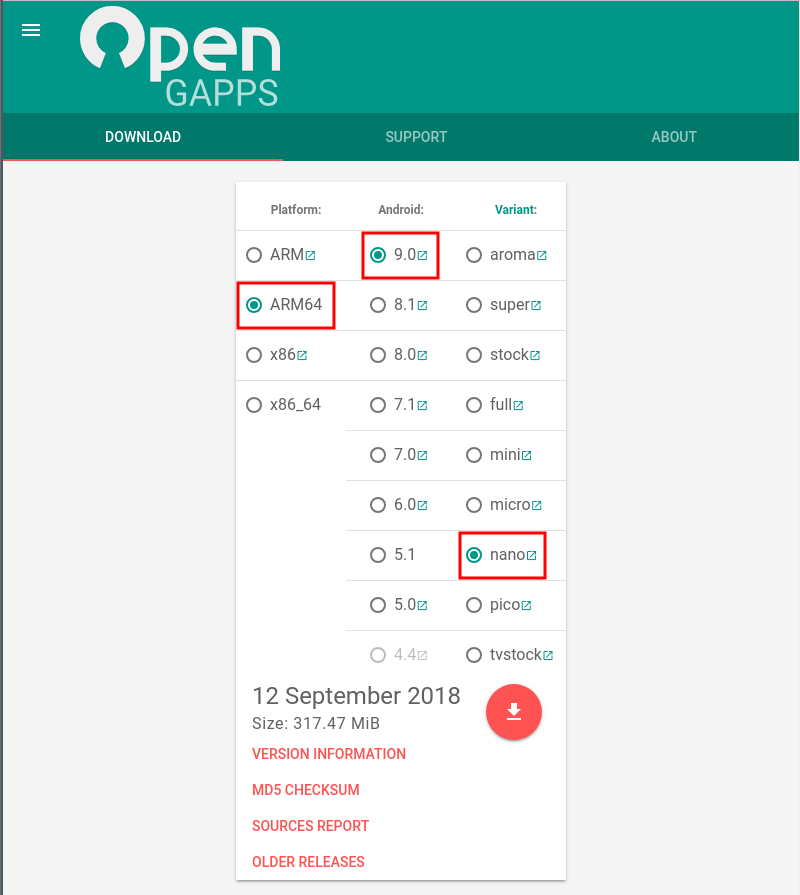
Google系のアプリはOpenGappsを利用する。既にOpenGappsの公式でAndroid 9.0対応のバージョンが配布されているので8.0の頃のように野良ビルドを探して回る必要はない。
Zenfone 2 Laserはたしか全機種ARM64。Androidバージョンは今回は9.0。Variantは本来は普通にアプリが揃う程度のminiあたりを選択するところだが、今回はインストール時にError 70が出たのでもっとコンパクトなパッケージのnano, picoあたりを選ぶ。足りないアプリは後でGoogle Playからインストールする。今回はnanoでインストール成功を確認している。
TWRP
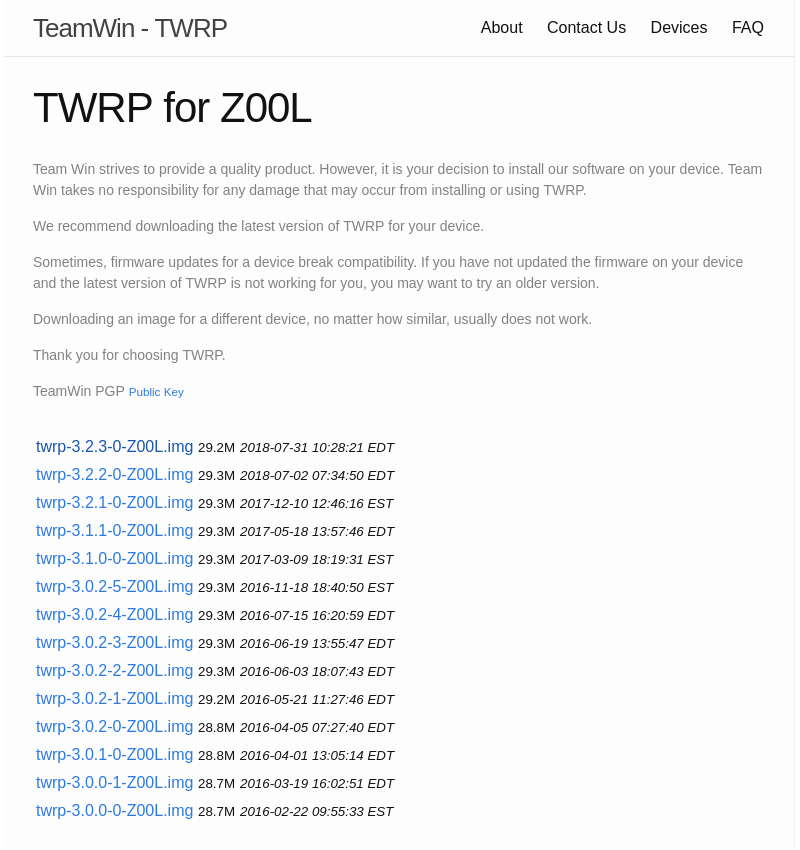
OSイメージを電話機に書き込むカスタムリカバリはいつものようにTWRP(デバイス別)を利用する。まだインストールしていないとか古いバージョンを使っているということであればなるべく新しいバージョンをインストールする方が無難。インストール時と同じ方法で上書きするだけ。
Root化して使うというなら最初のXDAのスレッドのダウンロードリンクの次のRoot addonの行にMagisk 17.1以降を使えとあるのでそれに従う。
インストール
インストール方法はLineageOS 15.0のときと同じ
起動して触ってみた

初起動はしばらく時間がかかる。上の画像の画面が出たら2〜5分待ってからAndroidの初期設定を行う。待っている間に画面が消えたら電源ボタンを1度押す。
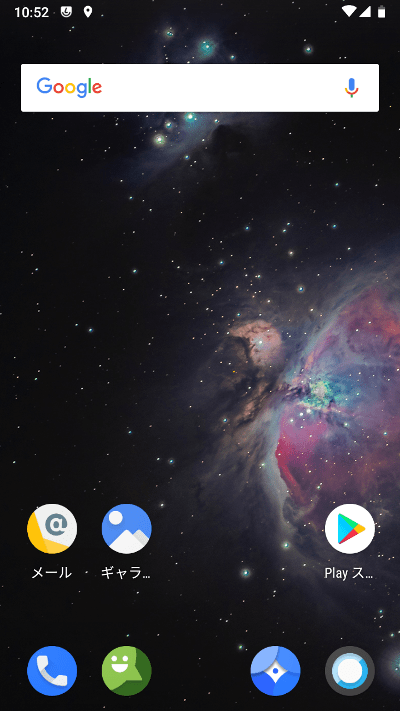
初期設定の直後の画面。Android 8.1や LineageOS 15.1までと違うのは最上部の時計の位置くらい?

ドロワーは変わらないかな?上の画像ではドロワーの背景が灰色だけど、背景画像を変えると応じて色が変わるので黒系にもできる。
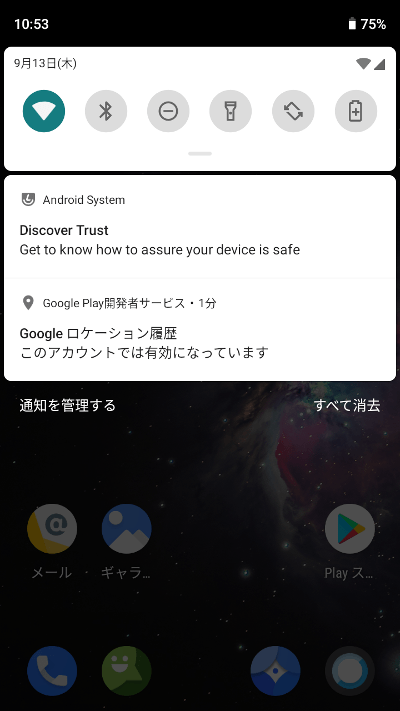
上から下へのスワイプ(の1段目)。これまでは通知エリアを開くためのスワイプ開始位置は例えば画面の中心など比較的どこからでも行えたが、LineageOS 16では指を画面最上段のステータスバーから下に滑らせないと通知エリアが開かない。ステータスバーの幅が狭いこともあって少しやりにくい。
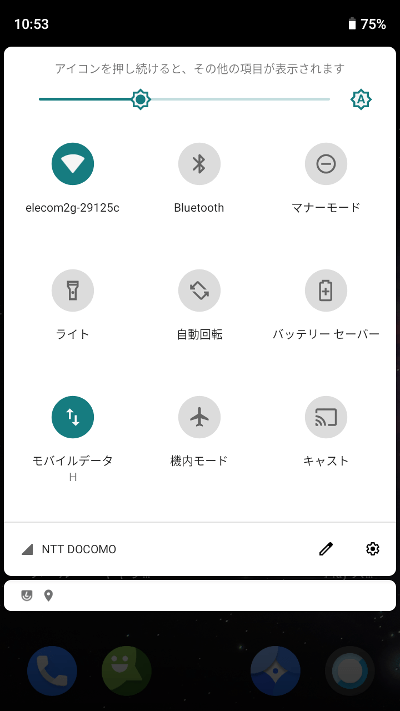
上から下へのスワイプ(の2段目)または2本指での上から下へのスワイプ。
1段目から2段目を開くときはスワイプ開始位置はどこでも良いみたい。1段目を開いていない状態で2本指の下スワイプは1段目を開く時と同じくステータスバーからスワイプしないとダメ。
設定メニューは代わり映えしない。
Android 9 Pieで設定に追加されたDigital Wellbeingというやつ。便利というよりお節介な感じ。使うことあるかしら?
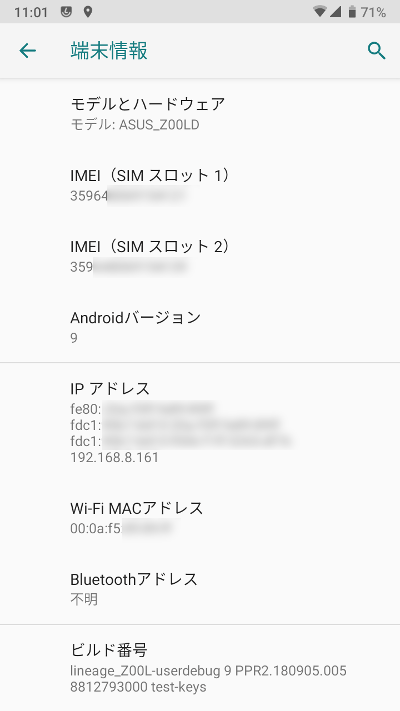
端末情報の表示は一新されているみたい。慣れのせいだろうが、これまでの表示の方が情報が見やすかった。
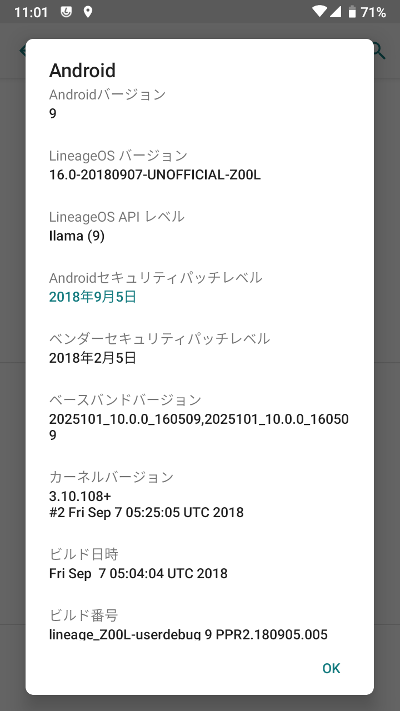
1つ前の画面でAndroidバージョンの項目をタップ。セキュリティパッチレベルはこの画面に表示される。一応最新版の9月5日のまで当たっているという表示になっている。(この情報が本当かどうかは未確認)

Androidバージョンをタップした画面に再びAndroidバージョンの項目があるけど、これを連続タップするとAndroid 9 Pieのイースターエッグ。
指でグルグルしたり2本指で触って遊ぶ?みたい。
ちなみにAndroidバージョンの下のLineageOSバージョンを連続タップするとLineageOSのイースターエッグが開くが、こちらは以前と変わらず伸びるクラゲっぽい何かだった。
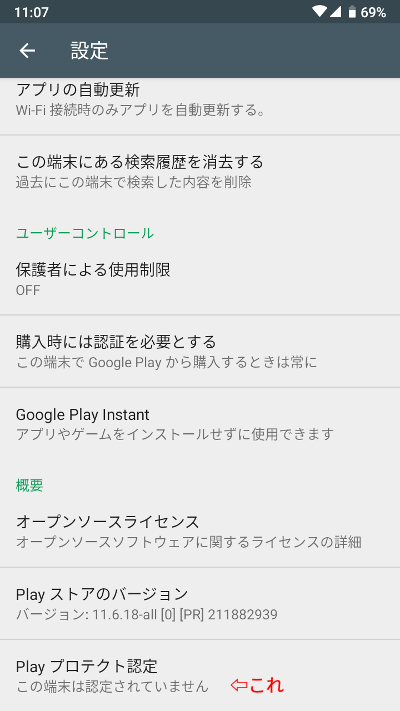
Androidの設定は終わりで、こんどはGoogle Playの設定画面。
一番下のPlay プロテクト認定を見てみたが、「この端末は認定されていません」だった。残念。
Android 8.1, LineageOS 15.1まではアプリの切り替え(右ボタン長押し)は縦スクロールだったのがAndroid 9 Pie, LineageOS 16は横スクロールになった。選び間違い防止の面では横スクロールでアプリ画面全体の縮小表示の方が良さそうだが、1画面に最大で3つのアプリしか表示されなくて、しかも全体表示は1アプリだけというのは一覧性は悪い。せめて横画面にしたら最大5つ表示するくらいして欲しかったところ。
USBケーブルを接続したときの切り替え画面。通知画面から表示するやつ。ポップアップ風ではなく専用1画面に変わった。
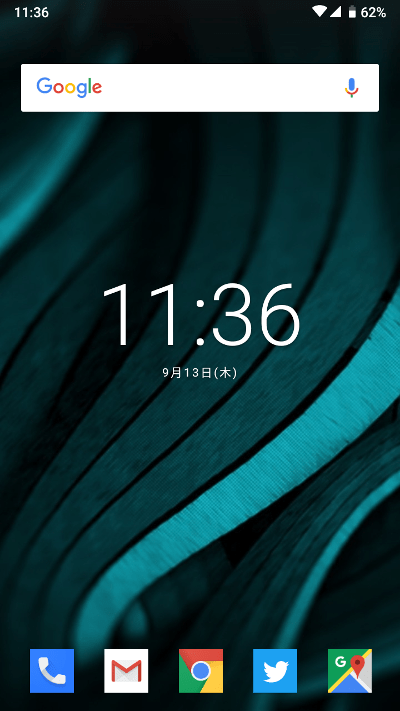
背景画像を変えて画面中央に大きめの時計を置いてアイコンを四角に切り替えた。Android4.xの頃からと代わり映えしない地味なホーム画面だが、慣れてるのが一番。アイコンの形は初期値の丸型の他に角丸、涙型、四角がある。以前から不思議に思ってるんだけど、四角アイコンはUnofficialではバージョンが進むと排除される、公式では採用されないの何でかしら?

カメラアプリは左から右にスワイプすると静止画・動画の切り替えと解像度設定。これは知らないと動画を撮れないかのように勘違いしそう。右から左へのスワイプは撮影済み画像のプレビュー・削除など。
そして、Zenfone 2 LaserのLineageOS 15, 15.1では動画が撮れないという不具合が長く続いたがLineageOS 16では既に余裕で撮れる。画質も悪くない。

カメラ(静止画モード)も綺麗に撮れるが、HDRだけは機能しているようでいて逆に作用しているかまたは機能が壊れている。
公式LineageOS 15.1の2018年7月の2つの版ではカメラが使い物にならないので正常に使える分こちらの方が優秀。
BluetoothとVoLTEの着信が問題「らしい」ということ以外はすでに実用できるレベルと言って過言ではない出来。LTEでは着信音も通話も正常なのを確認している。
もっとも気に入ったのは全般の反応の良さ。正直なところAndroid 9 PieでARTのパフォーマンスが改善したっていうのはMicrosoftがWindowsの新しいのを出す度に速くなった速くなったって自慢するのと同じくらい眉唾だったけど、実際にスッサッと動くので使ってて気持ち良いというかニヤけるほど嬉しい。だからLineageOS 15.1にはもう戻さない予定。
今後開発が進んでLineageOS 16が公式リリースということになればZenfone 2 LaserはAndroid 5.0から9相当までというかなり息の長い機種になりそう。