記事を書いといてなんだけど、超強力専用ハードウエアを使ってさえ投資と日本の電気代を考えると採算が合わないのが今のBitcoinの採掘。当然NanoPi NEOごときでは広大な畑を耳かきで土をすくって耕そうとするようなもので、非効率すぎて利益になることは100%ない。2017年の今となっては(NanoPiを母艦にして)USBのASIC採掘機を使ってもそれは基本的に変わらない。Bitcoin以外の割の良い暗号通貨でもNanoPiで採掘は利益が出ることはない、というか利益を考えること自体ナンセンス。
とりあえずNanoPiでもやろうと思えばできなくはないよ程度。
まず、マイニング用のソフトウエアを用意する。今回はpooler's cpuminerを使うこととする。
素のarmbianではpooler's cpuminerのコンパイルに必要なものが幾つか足りないので入れておく。
# apt-get install libcurl4-openssl-dev # apt-get install libjansson-dev # apt-get install autogen
もちろん入れたいパッケージ名を並べてapt-get 1回でも構わない。
入手したpooler's cpuminerのディレクトリ(ZIPで入手したなら展開したディレクトリ内)で以下。
$ ./autogen.sh $ ./configure CFLAGS="-O3" $ make
ここまで最新版のビルド方法。(/usr/内にインストールするならmake installするなり)
NanoPi NEOのarmbianには幾つか前の記事にも書いたarmbianmonitorで何故かpooler's cpuminerをインストールできる。当然こちらの方が圧倒的に簡単。
# armbianmonitor -p
minerdが出来ている筈なので確認がてら使用方法を見る。
$ ./minerd --help ←上のGitHubからの場合 $ minerd --help ←上のarmbianmonitorでインストールした場合 Usage: minerd [OPTIONS] Options: -a, --algo=ALGO specify the algorithm to use scrypt scrypt(1024, 1, 1) (default) scrypt:N scrypt(N, 1, 1) sha256d SHA-256d -o, --url=URL URL of mining server -O, --userpass=U:P username:password pair for mining server -u, --user=USERNAME username for mining server -p, --pass=PASSWORD password for mining server --cert=FILE certificate for mining server using SSL -x, --proxy=[PROTOCOL://]HOST[:PORT] connect through a proxy -t, --threads=N number of miner threads (default: number of processors) -r, --retries=N number of times to retry if a network call fails (default: retry indefinitely) -R, --retry-pause=N time to pause between retries, in seconds (default: 30) -T, --timeout=N timeout for long polling, in seconds (default: none) -s, --scantime=N upper bound on time spent scanning current work when long polling is unavailable, in seconds (default: 5) --coinbase-addr=ADDR payout address for solo mining --coinbase-sig=TEXT data to insert in the coinbase when possible --no-longpoll disable long polling support --no-getwork disable getwork support --no-gbt disable getblocktemplate support --no-stratum disable X-Stratum support --no-redirect ignore requests to change the URL of the mining server -q, --quiet disable per-thread hashmeter output -D, --debug enable debug output -P, --protocol-dump verbose dump of protocol-level activities -S, --syslog use system log for output messages -B, --background run the miner in the background --benchmark run in offline benchmark mode -c, --config=FILE load a JSON-format configuration file -V, --version display version information and exit -h, --help display this help text and exit
マイニング実行
$ ./minerd --url=http://example.com:1234 --userpass=user:password
採掘用のプールとして例えばSlush Poolを使っているとするならURLはstratum+tcp://stratum.slushpool.com:3333。東アジア直指定ならstratum+tcp://sg.stratum.slushpool.com:3333 (シンガポール)。ユーザー名とワーカー名をピリオドで繋ぐ、それとパスワードをコロン「:」で繋ぐ。パスワードは何でも。他の採掘者になりすますバカはいないのでそれで良いかと。今回はBitcoinなのでアルゴリズムはsha256dを指定する。Litecoinなどはscryptだが、これはminerdの初期値なので指定無しで良い。(非力なCPUやGPUで採掘するならASICが力を発揮できないscryptで採掘する暗号通貨の方が良さげ。)
こんな感じ
$ ./minerd --algo=sha256d --url=stratum+tcp://sg.stratum.slushpool.com:3333 --userpass=username.worker1:anything
上の例ではフォアグラウンドで実行しているので逐次状況が表示される。
[2017-02-28 19:47:31] thread 0: 21110861 hashes, 351.63 khash/s [2017-02-28 19:47:32] thread 2: 21161664 hashes, 352.48 khash/s [2017-02-28 19:47:32] thread 3: 21123848 hashes, 352.21 khash/s [2017-02-28 19:47:32] thread 1: 21115858 hashes, 352.07 khash/s [2017-02-28 19:48:23] thread 0: 18122136 hashes, 351.00 khash/s [2017-02-28 19:48:23] accepted: 1/1 (100.00%), 1408 khash/s (yay!!!)
しばらくというか数時間ほど様子を見て上のように(yay!!!)が表示されるなら正常。(booooo)ばかり表示されるなら何かがおかしいかも。
表示されているハッシュレートの数字の可愛らしいこと。ASICのAvalon6が3.5Thash/s (消費電力980W)、Avalon721が6Thash/s (同900W)ということらしいのでやはりASICとは桁桁桁違い。
なお、Slush PoolではcgminerとBFGminerだけをサポートしていてminerdは非サポートと明示している。ASIC以外はお呼びじゃないとのこと。pooler's cpuminerで上手くいかなくても文句は言えない。
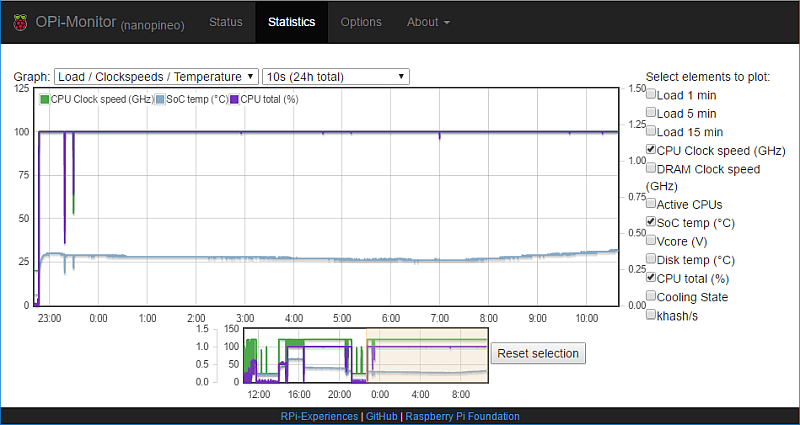
Bitcoin採掘時、CPU使用率は100%張り付き(紫線・左目盛り)、CPUクロックは最高値の1.2GHz(緑線・右目盛り)張り付きだが、ちょうど左目盛り100%と右目盛り1.2GHzが重なる高さにあるので緑線が紫線に隠れている。SoCの温度(水色線・左目盛り)は、前回までと同様に机の上に置いて風に当てない状態だと60℃まで上昇してオーバーヒート防止の為のクロックダウンが発生してしまうので空気清浄機から吹き出す風が僅かに当たる場所に置いたところ全力運転で30℃前後に抑えられている。
なお、グラフ左の方の23時台に2回縦線が発生しているところは短時間だがBitcoinの採掘を停止したのが反映されている。
- NanoPi NEO3にGPSモジュールを接続してNTPサーバとして使用する
- アッチッチなNanoPi NEO3を冷やしたい パッド交換
- NanoPi NEO3冷却力強化後のUnixBench
- アッチッチなNanoPi NEO3を冷やしたい
- NTPサーバの時刻ソースに対するズレの調整
- NanoPi NEO3をv6プラスのルーターにする systemd-networkd + nftables
- NanoPi NEO3のUSB3.0ポートのネットワーク速度
- NanoPi NEO3でArmbian よきところでUnixBench
- NanoPi NEO3が届いた
- NanoPi NEOにRTCモジュールを付ける
- 新しい中華GPSモジュールとChronyで作るNTPサーバ (中編)
- 新しい中華GPSモジュールとChronyで作るNTPサーバ (前編)
- Prometheus2とGrafana6によるシステム監視 シングルボードコンピュータの温度表示
- NanoPi NEOでNTPサーバ再構築 (全まとめ)
- NanoPi NEO2をv6プラスのルーターにする 後編
- NanoPi NEO2をv6プラスのルーターにする 前編
- ELK Stackでシステム監視 FilebeatでNTP統計ログ取得 Logstashで加工
- NanoPi NEO2(arm64)用にFilebeatをビルド
- NanoPi NEO2を超コンパクトなアルミケースに入れる
- NanoPi NEO2用armbian 5.41 Debian 9 Stretch next 4.14.18
- NanoPi NEO2を100均の灰皿に入れてみた
- NanoPi NEO2のシステム監視 RPi-Monitorとnetdata
- NanoPi NEOとGPSモジュール用アルミケースを作る
- NanoPi NEO2 + DACで音楽プレーヤーVolumioを使う
- NanoPi NEO2にDACを接続
- NanoPi NEO2の最大クロック引き下げ後のUnixBench 再び
- NanoPi NEO2用armbian 5.32 Debian 9 Stretch 4.13.0-RC6
- NanoPi NEO2用armbian 5.32 Debian jessie 4.13.0-RC6
- NanoPi NEOをSIP電話機にする 後編 (その2)
- NanoPi NEO2とICカードリーダーでタイムレコーダーを作る(実用化編)